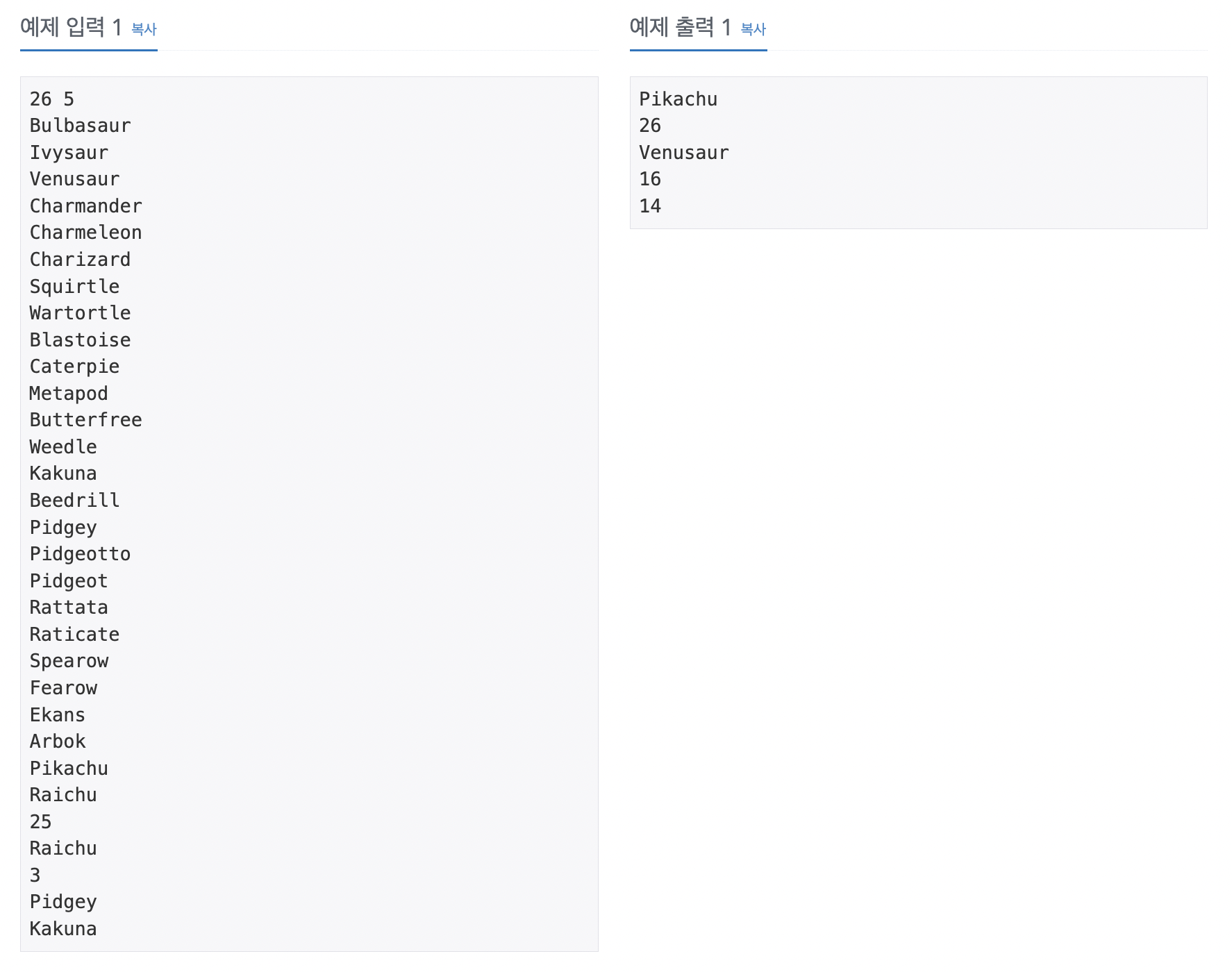
Hash 맵을 이용 해서 푸는 문제이다. HashMap을 이용해서 <String, String>으로 받아 key와 vlaue를 두 개를 저장을 한다. 하나는 i를 String으로 바꿔서 key, 포켓몬 이름은 value를 넣어주고 다른 하나는 두 개를 바꿔서 저장을 한다. 답의 출력을 받을 때 받은 것이 숫자인지 문자인지 판별하는 메서드를 만들어서 true, false로 반환한다. 그리고 StringBuilder를 이용하여 정답을 출력한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek1620 {
static String str;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
HashMap<String, String> map = new HashMap<>();
for(int i = 1; i <= n; i++) {
String ss = br.readLine();
String num = Integer.toString(i);
map.put(num, ss);
map.put(ss, num);
}
StringBuilder sb = new StringBuilder();
for(int i = 0; i < m; i++) {
str = br.readLine();
if(isInteger()) {
sb.append(map.get(str) + "\\n");
}
else {
sb.append(map.get(str) + "\\n");
}
}
System.out.println(sb.toString());
}
private static boolean isInteger() {
for(int j = 0; j < str.length(); j++) {
if(Character.isDigit(str.charAt(j))) {
return true;
}
}
return false;
}
}
문제점
실버 4의 문제이고 쉬운 문제라고 생각했다. 문제를 푸는데는 어려움이 없었지만 계속 시간 초과가 발생했다. 숫자인지 판별해주는 메소드를 만들지 않았고 문제를 풀 때 map에 key, value 하나만 저장해 vlaue를 이용해 key값을 가져오려고 하였다. 여기서 시간 초과가 발생했다. 방법이 떠오르지 않아 이를 key, value를 바꿔서 하나 더 저장하는 아이디어를 검색을 해서 찾았습니다.
오늘의 회고
오늘은 쉬운 알고리즘 문제 한문제를 풀고 그동안 풀었던 알고리즘 개념을 다시 정리하면서 블로그에 작성하려고 합니다. 반복적인 복습과 꾸준한 학습으로 점점 더 발전하는 개발자가 되겠습니다.
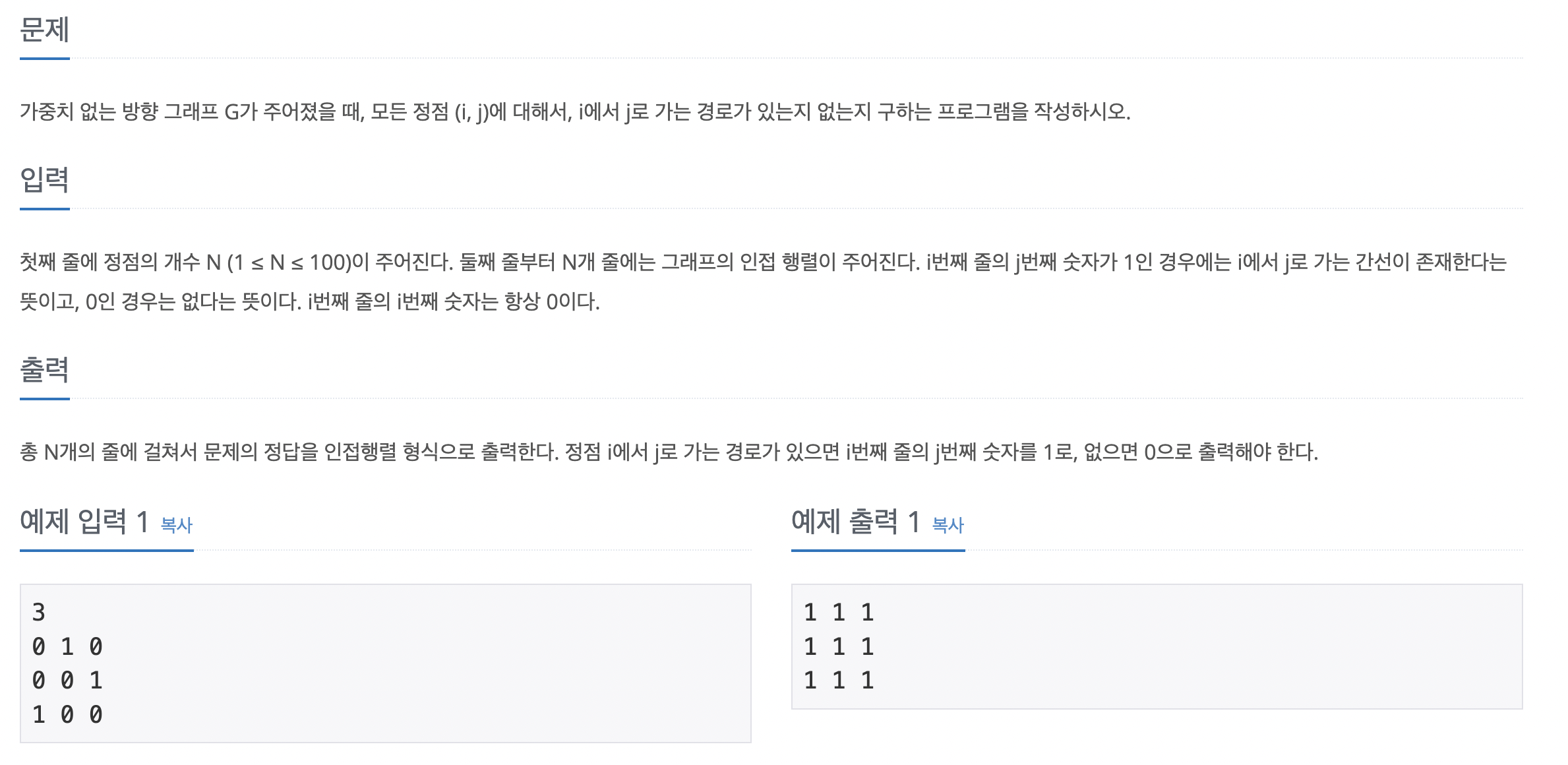
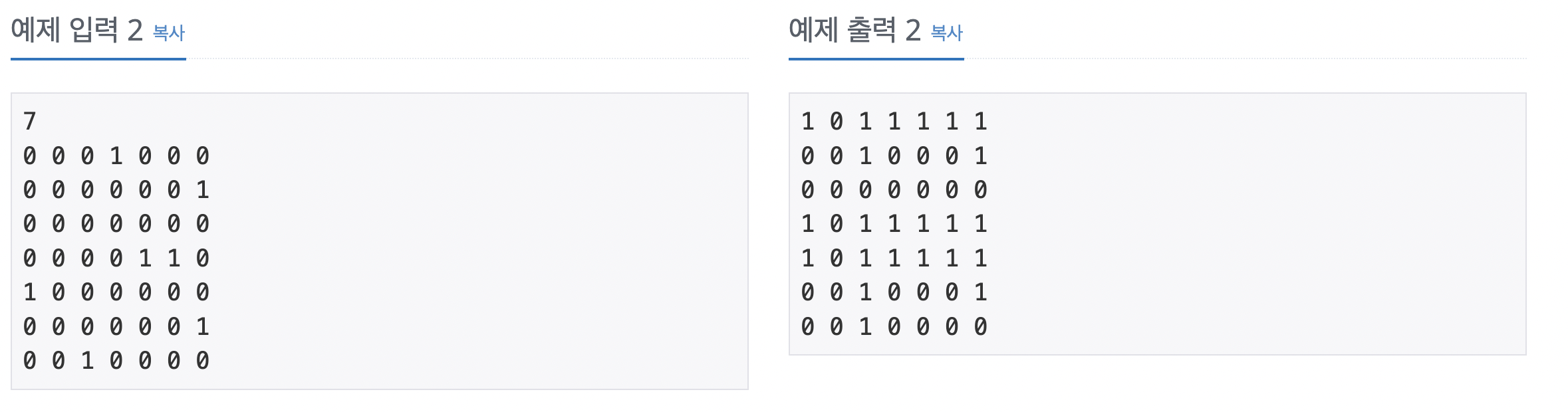
어제 배운 플로이드-위셜 기본 문제이다. 모든 노드 쌍에 관해 경로가 있는지 여부를 확인하는 방법은 플로이드-위셜 알고리즘을 수행해 결과 배열을 그대로 출력하면 된다. 입력 데이터를 인접 행렬에 저장한다. s와 e가 모든 중간 경로(k) 중 1개라도 연결돼 있다면 s와 e는 연결 노드로 저장한다. 변경된 인접 행렬을 출력한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek11403 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int[][] arr = new int[n + 1][n + 1];
for(int i = 1; i <= n; i++) {
StringTokenizer st = new StringTokenizer(br.readLine());
for(int j = 1; j <= n; j++) {
arr[i][j] = Integer.parseInt(st.nextToken());
}
}
for(int k = 1; k <=n; k++) {
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
if(arr[i][k] == 1 && arr[k][j] == 1) {
arr[i][j] = 1;
// k를 거치는 모든 경로 중 1개라도 연결돼 있는 경로가 있다면 i와 j는 연결 노드로 취급
}
}
}
}
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
System.out.print(arr[i][j] + " ");
}
System.out.println();
}
}
}
63번 케빈 베이컨의 6단계 법칙
내가 떠올린 풀이 해설
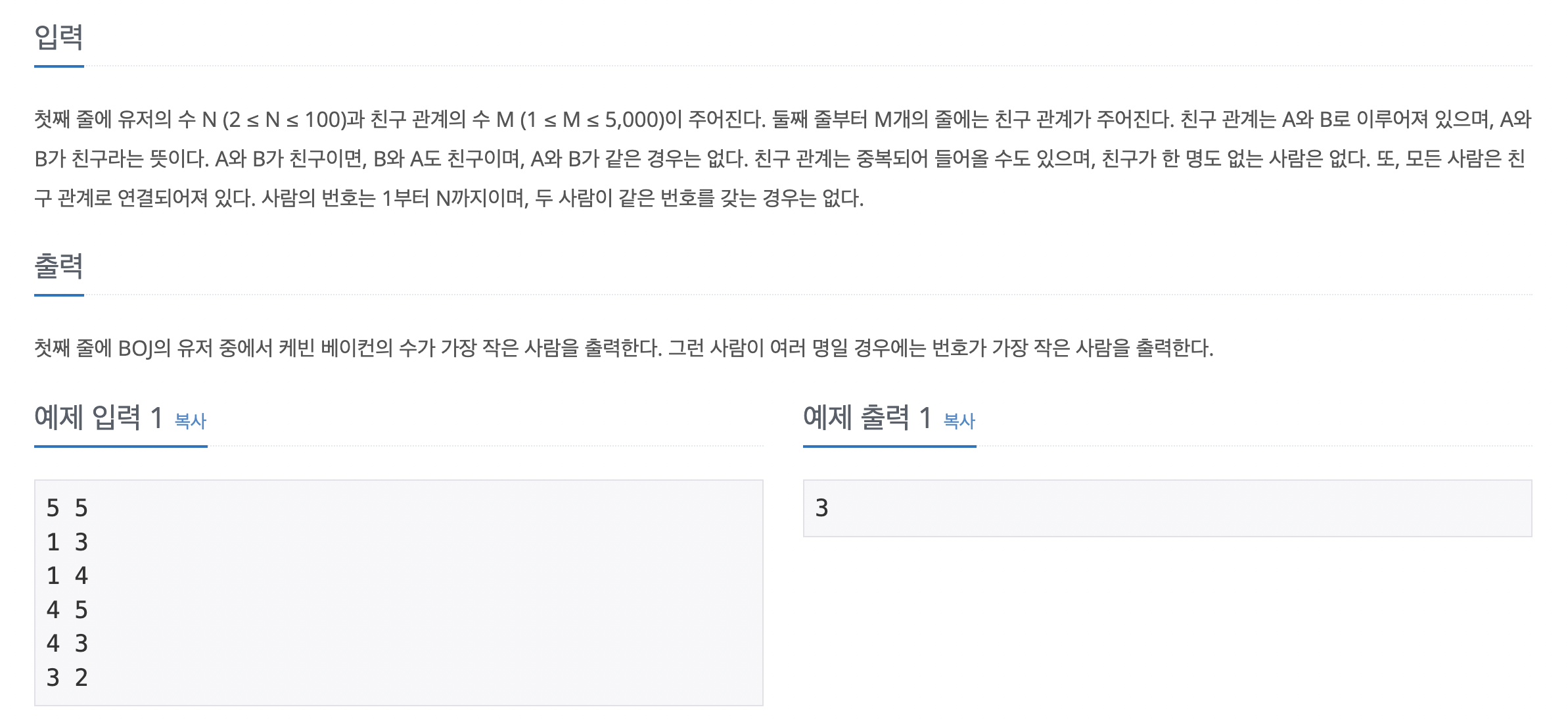
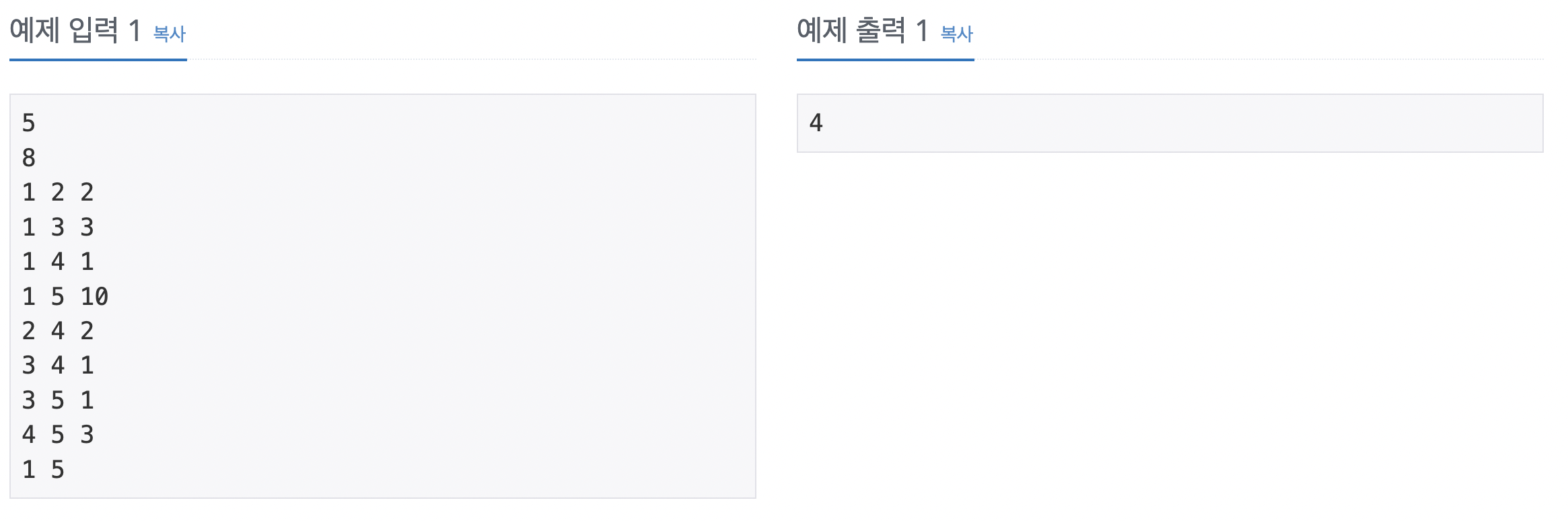
BFS를 이용해서도 풀 수 있는 문제이다. 이 문제를 풀기 위해 몇가지 아이디어가 필요하다. 1번째로 사람들이 직접적인 친구 관계를 맺은 상태를 비용 1로 계산하는 것이다. 즉 가중치를 1로 정한 후 인접 행렬에 저장한다는 의미이다. 또한 플로이드-위셜은 모든 쌍과 관련된 최단 경로이므로 한 row의 배열 값은 이 row의 index값에서 다른 모든 노드와 관련된 최단 경로를 나타낸다고 볼 수 있다. 즉 i번째 row의 합이 i번째 사람의 케빈 베이컨의 수가 된다는 뜻이다.
먼저 인접 행렬을 생성한 후, 자기 자신이면 0, 아니면 충분히 큰 수로 인접 행렬의 값을 초기화한다. 그리고 친구 관계 정보를 인접 행렬에 저장한다. i와 j가 친구라면 arr[i][j] = 1, arr [j][i] = 1로 값을 업데이트한다. 플로이드-위셜 3중 for문으로 모든 중간 경로를 탐색한다. 케빈 베이컨의 수를 비교해 가장 작은 수가 나온 행 번호를 정답으로 출력한다. 같은 수가 있을 때는 더 작은 행 번호를 출력한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek1389 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
int[][] arr = new int[n + 1][n + 1];
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
if(i == j) {
arr[i][j] = 0;
}
else {
arr[i][j] = 1000001;
}
}
}
for(int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
int s = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
arr[s][e] = 1;
arr[e][s] = 1;
}
for(int k = 1; k <= n; k++) {
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
arr[i][j] = Math.min(arr[i][j], arr[i][k] + arr[k][j]);
}
}
}
int sum = 0;
int answer = Integer.MAX_VALUE;
int index = 0;
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
sum += arr[i][j];
}
if(answer > sum) {
answer = sum;
index = i;
}
sum = 0;
}
System.out.println(index);
}
}
오늘의 회고
오늘은 어제 배운 플로이드-위셜 문제를 풀고 최소 신장 트리(MST) 이론을 학습하였습니다. 최소 신장 트리를 코드로 나타내는 것에 어려움을 많이 느꼈습니다. 주말에는 지금까지 풀었던 문제 복습과 배웠었던 알고리즘 이론들을 까먹지 않고 반복적으로 보기 쉽게 블로그에 정리하려고 합니다. 오늘은 퇴사 후 1달 정도가 되었는데 처음 알고리즘을 공부하였을 때 브론즈 5였는데 오늘은 골드 5를 찍었습니다. 앞으로 더 열심히 하겠습니다.
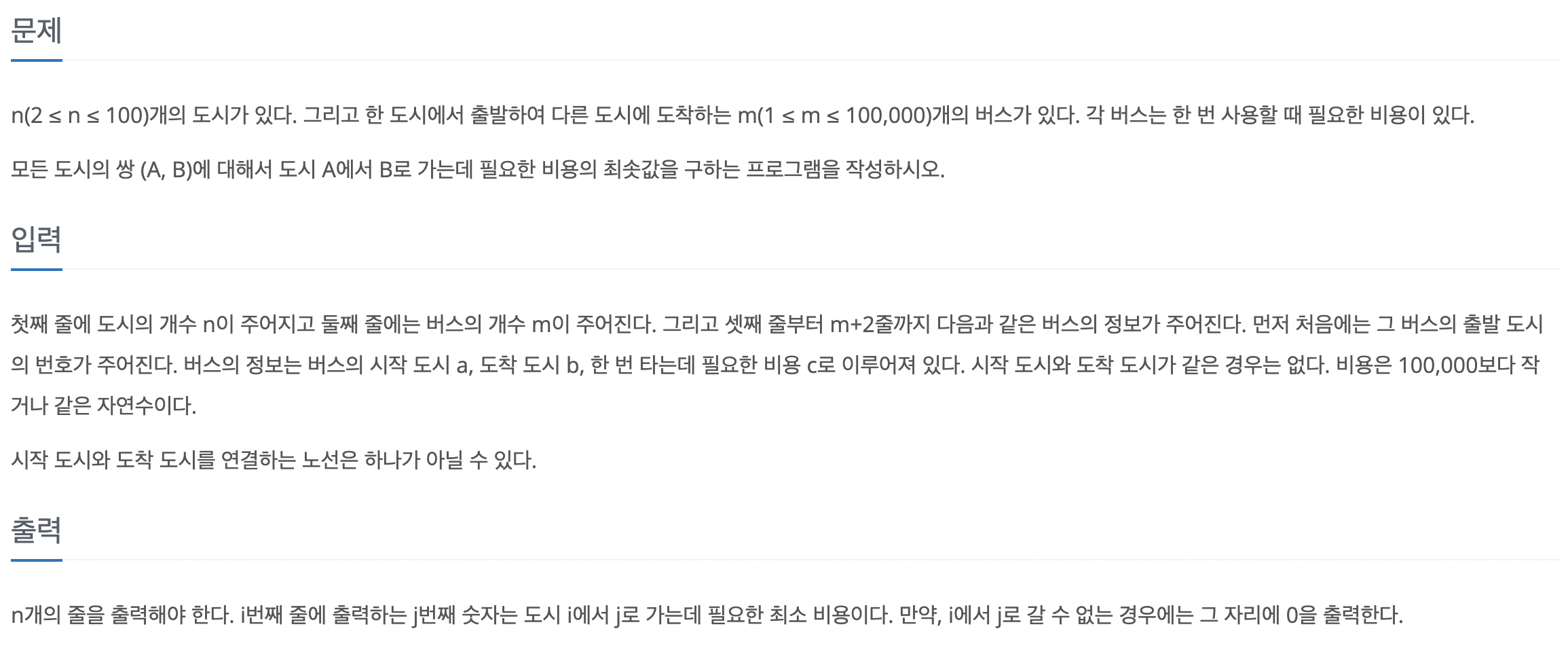
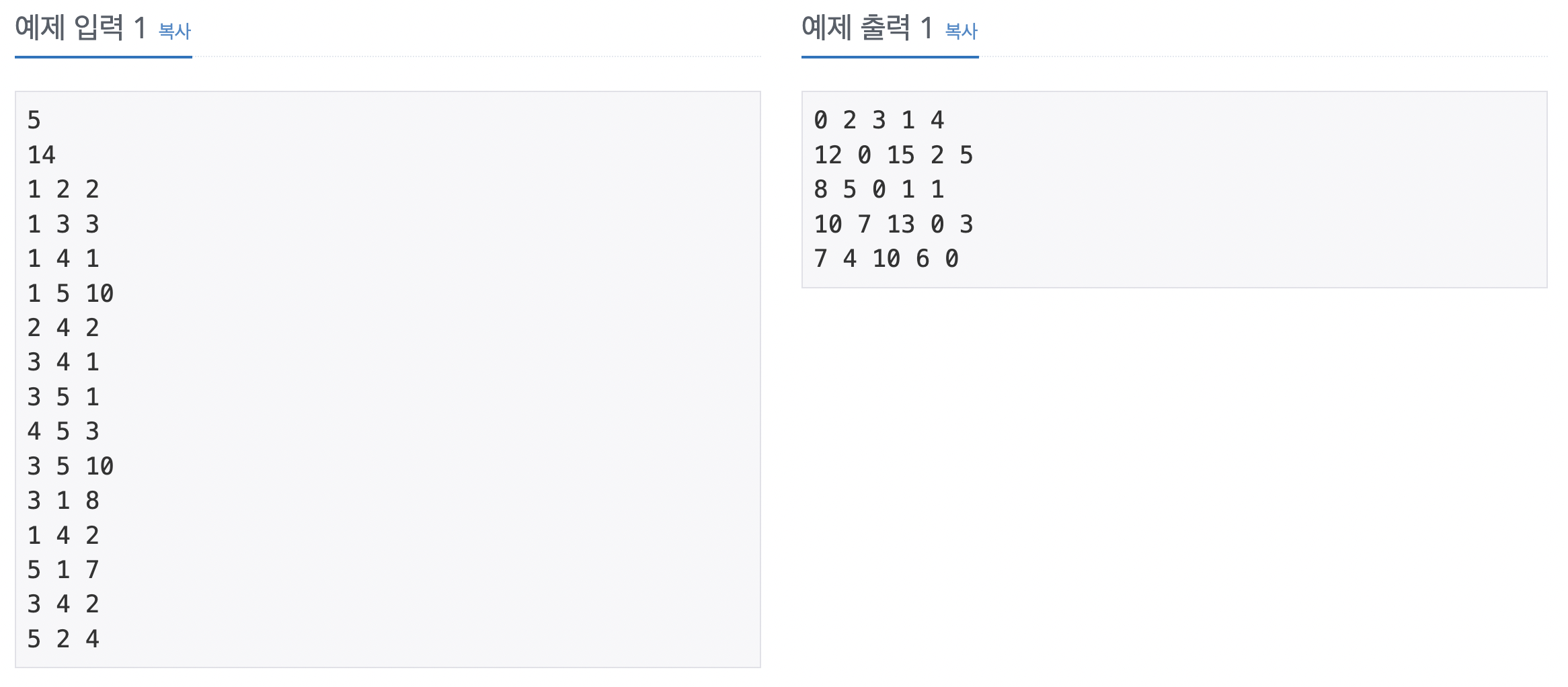
모든 도시에 쌍과 관련된 최솟값을 찾아야 하는 문제이다. 그래프에서 시작점을 지정하지 않고, 모든 노드와 관련된 최소 경로를 구하는 알고리즘인 플로이드-위셜을 사용해야 된다. 도시의 최대 개수가 100개로 매우 작은 편이므로 O(N^3)인 플로이드-위셜을 사용할 수 있다.
버스 비용 정보를 인접 행렬에 저장한다. 연결 도시가 같으면 0, 아니면 큰 수 값으로 초기화한다. 그리고 주어진 버스 비용 데이터값을 인접 행렬에 저장한다. 플로이드-위셜 알고리즘을 수행한다. 3중 for 문으로 모든 중간 경로를 탐색한다. 알고리즘으로 변경된 인접 행렬을 출력한다. 문제의 요구사항에 따라 두 도시가 도달하지 못할 때는 0, 아닐 때는 배열의 값을 출력한다.
*플로이드 위셜-점화식
Math.min(arr[s][e], arr[s][k] + arr[k][e])
for(k -> n만큼 반복하기) { // 3중 for문의 순서가 중요함 k가 가장 바깥쪽
for(i -> n만큼 반복하기) {
for(j -> n만큼 반복하기) {
arr[i][j]에 arr[i][k] + arr[k][j] 값들 중 최솟값 넣기
i ~ j 사이에 가능한 모든 경로를 탐색하기
}
}
}
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek11404 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int m = Integer.parseInt(br.readLine());
int[][] arr = new int[n + 1][n + 1];
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
if(i == j) {
arr[i][j] = 0;
}
else {
arr[i][j] = 10000001;
}
}
}
for(int i = 0; i < m; i++) {
StringTokenizer st = new StringTokenizer(br.readLine());
int s = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
if(arr[s][e] > v) {
arr[s][e] = v;
}
}
for(int k = 1; k <= n; k++) {
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
if(arr[i][j] > arr[i][k] + arr[k][j]) {
arr[i][j] = arr[i][k] + arr[k][j];
}
}
}
}
for(int i = 1; i <= n; i++) {
for(int j = 1; j <=n; j++) {
if(arr[i][j] == 10000001) {
System.out.print("0 ");
}
else {
System.out.print(arr[i][j] + " ");
}
}
System.out.println();
}
}
}
오늘의 회고
오늘은 플로이드-위셜 알고리즘 개념을 배웠습니다. 플로이드-위셜은 코드가 많이 어렵지 않아 쉽게 이해할 수 있었습니다. 아직 배울 알고리즘이 많이 남았습니다. 천천히 꾸준히 배워 나아가겠습니다.
버스의 비용의 범위가 음수가 아니기 때문에 이 문제는 다익스트라 알고리즘을 이용해 해결할 수 있다. 도시의 개수가 최대 1,000개 이므로 인접 행렬 방식으로 해결할 수 있지만 인접 리스트로 풀었다. 도시는 노드, 도시 간 버스 비용은 에지로 나타낸다.
도시 개수의 크기만큼 인접 리스트 배열의 크기를 설정한다. 이때 버스의 비용이 존재하므로 인접 리스트 배열의 자료형이 될 클래스를 선언한다. 그리고 버스 개수의 크기만큼 반복문을 돌면서 그래프를 리스트 배열에 저장한다. 다익스트라 알고리즘을 수행한다. 최단 거리를 완성되면 출력한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek1916 {
static int n, m;
static ArrayList<Node>[] list;
static boolean[] visit;
static int[] distance;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st;
n = Integer.parseInt(br.readLine());
m = Integer.parseInt(br.readLine());
list = new ArrayList[n + 1];
visit = new boolean[n + 1];
distance = new int[n + 1];
for(int i = 0; i <= n; i++) {
list[i] = new ArrayList<Node>();
}
for(int i = 0; i <= n; i++) {
distance[i] = Integer.MAX_VALUE;
}
for(int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
int s = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
list[s].add(new Node(e, v));
}
st = new StringTokenizer(br.readLine());
int start = Integer.parseInt(st.nextToken());
int end = Integer.parseInt(st.nextToken());
dijkstra(start, end);
System.out.println(distance[end]);
}
private static int dijkstra(int start, int end) {
PriorityQueue<Node> que = new PriorityQueue<>();
que.offer(new Node(start, 0));
distance[start] = 0;
while(!que.isEmpty()) {
Node cur = que.poll();
int c_v = cur.vertex;
if(!visit[c_v]) {
visit[c_v] = true;
for(Node n : list[c_v]) {
if(!visit[n.vertex] && distance[n.vertex] > distance[c_v] + n.value) {
distance[n.vertex] = distance[c_v] + n.value;
que.add(new Node(n.vertex, distance[n.vertex]));
}
}
}
}
return distance[end];
}
}
class Node implements Comparable<Node>{
int vertex;
int value;
public Node(int vertex, int value) {
this.vertex = vertex;
this.value = value;
}
@Override
public int compareTo(Node o) {
return value - o.value;
}
}
59번 타임머신
내가 떠올린 풀이
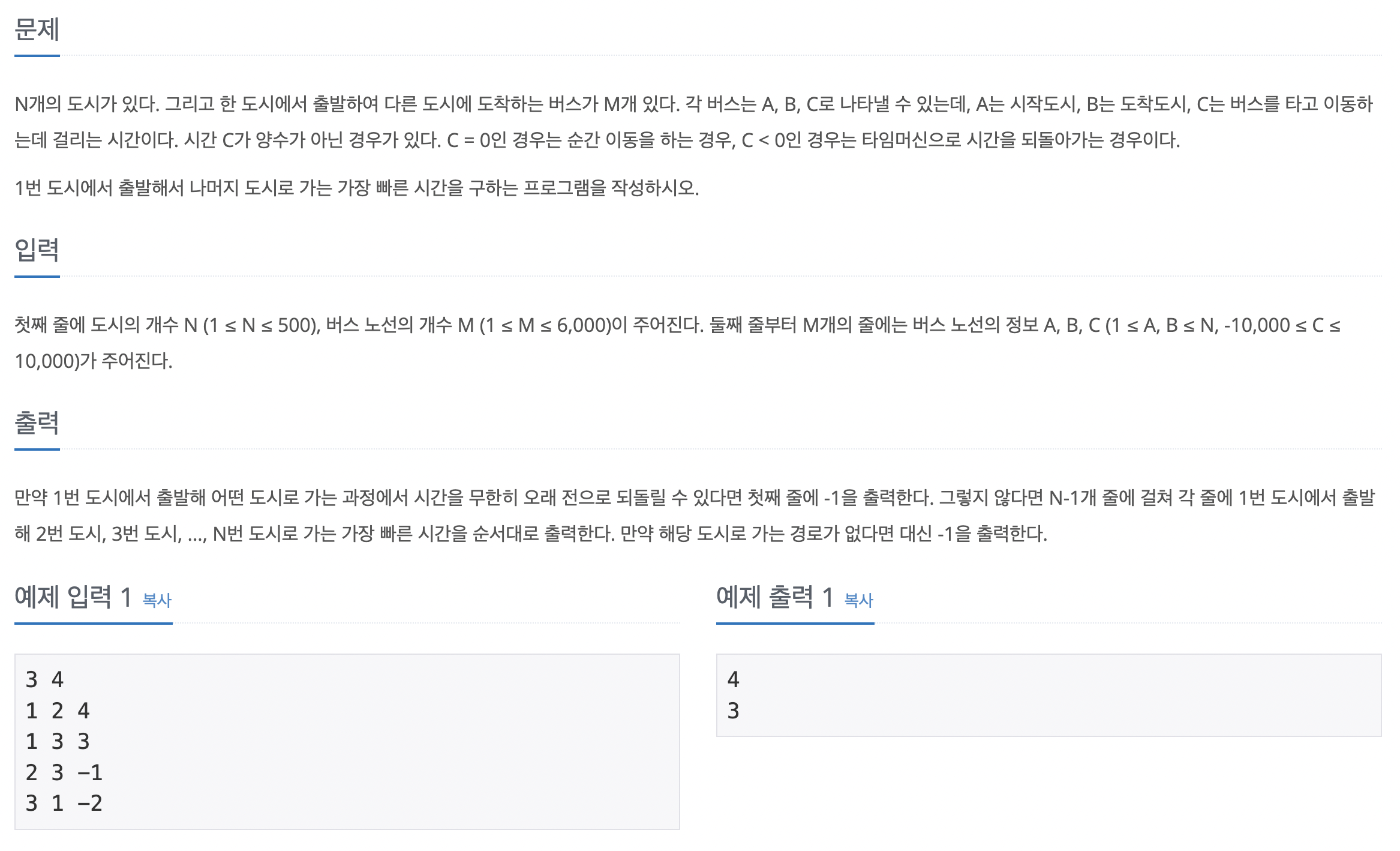
에지 리스트에 에지 데이터를 저장한 후 거리 배열을 초기화한다. 최초 시작점에 해당하는 거리 배열값은 0으로 초기화한다. 벨만-포드 알고리즘을 수행한다. 음수 사이클이 존재하면 -1, 존재하지 않으면 거리 배열의 값을 출력한다. 단, 거리 배열의 값이 INF일 경우에는 -1을 출력한다.
벨만-포드 수행과정
1. 모든 에지와 관련된 정보를 가져온 후 다음 조건에 따라 거리 배열의 값을 업데이트한다.
출발 노드가 방문한 적이 없는 노드(출발 노드 거리 == INF)일 때 값을 업데이트하지 않는다.
출발 노드의 거리 배열값 + 에지 가중치 < 종료 노드의 거리 배열 값일 때 종료 노드의 거리 배열 값을 업데이트한다.
2. 노드 개수 -1번만큼 1번을 반복한다.
3. 음수 사이클 유무를 알기 위해 모든 에지에 관해 다시 한번 1번을 수행한다. 이때 한 번이라도 값이 업데이트되면 음수 사이클이 존재한다고 판단한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek11657 {
static int n, m;
static long distance[];
static Edge edges[];
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
edges = new Edge[m + 1];
distance = new long[n + 1];
for(int i = 0; i <= n; i++) {
distance[i] = Integer.MAX_VALUE;
}
for(int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
int s = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
edges[i] = new Edge(s, e, v);
}
distance[1] = 0;
for(int i = 1; i < n; i++) {
for(int j = 0; j < m; j++) {
Edge edge = edges[j];
if(distance[edge.s] != Integer.MAX_VALUE
&& distance[edge.e] > distance[edge.s] + edge.v) {
distance[edge.e] = distance[edge.s] + edge.v;
}
}
}
boolean mCycle = false;
for(int i = 0; i < m; i++) {
Edge edge = edges[i];
if(distance[edge.s] != Integer.MAX_VALUE
&& distance[edge.e] > distance[edge.s] + edge.v) {
mCycle = true;
}
}
if(!mCycle) {
for(int i = 2; i <= n; i++) {
if(distance[i] == Integer.MAX_VALUE) {
System.out.println("-1");
}
else {
System.out.println(distance[i]);
}
}
}
else {
System.out.println("-1");
}
}
}
class Edge {
int s;
int e;
int v;
public Edge(int s, int e, int v) {
this.s = s;
this.e = e;
this.v = v;
}
}
오늘의 회고
오늘은 다익스트라 한 문제와 벨만-포드 알고리즘 개념과 관련된 문제를 풀었습니다. 아직 다익스트라와 벨만-포드 구현에 대해 많이 부족한 것 같습니다. 내일도 이와 관련된 문제들을 풀고 다시 한번 개념에 대해 공부하겠습니다.
파티에 참석한 사람들을 1개의 집합으로 생각하고, 각각의 파티마다 union연산을 이용해 사람들을 연결하는 것이 중요하다. 이 작업을 하면 1개의 파티에 있는 모든 사람들은 같은 대표 노드를 바라보게 된다. 이후 각 파티의 대표 노드와 진실을 알고 있는 사람들의 각 대표 노드가 동일한지 find연산을 이용해 확인함으로써 과장된 이야기를 할 수 있는지 판단할 수 있다. 진실을 아는 사람 데이터, 파티 데이터, 유니온 파인드를 위한 대표 노드 자료구조를 초기화한다. union연산을 수행해 각 파티에 참여한 사람들을 1개의 그룹으로 만든다. find 연산을 수행해 각 파티의 대표 노드와 진실을 아는 사람들이 같은 그룹에 있는지 확인한다. 파티 사람 노드는 모두 연결돼 있으므로 아무 사람이나 지정해 find 연산을 수행하면 된다. 모든 파티에 관해 과정을 반복해 수행하고, 모든 파티의 대표 노드가 진실을 아는 사람들과 다른 그룹에 있다면 결괏값을 증가시킨다. 과장할 수 있는 파티의 개수를 결괏값으로 출력한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek1043 {
static int[] trueP;
static ArrayList<Integer>[] party;
static int[] parent;
static int result = 0;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
st = new StringTokenizer(br.readLine());
int t = Integer.parseInt(st.nextToken());
trueP = new int[t];
for(int i = 0; i < t; i++) {
trueP[i] = Integer.parseInt(st.nextToken());
}
party = new ArrayList[m];
for(int i = 0; i < m; i++) {
party[i] = new ArrayList<>();
st = new StringTokenizer(br.readLine());
int people = Integer.parseInt(st.nextToken());
for(int j = 0; j < people; j++) {
party[i].add(Integer.parseInt(st.nextToken()));
}
}
parent = new int[n + 1];
for(int i = 0; i <= n; i++) {
parent[i] = i;
}
for(int i = 0; i < m; i++) {
int firstPeople = party[i].get(0);
for(int j = 1; j < party[i].size(); j++) {
union(firstPeople, party[i].get(j));
}
}
for(int i = 0; i < m; i++) {
boolean isPossible = true;
int cur = party[i].get(0);
for(int j = 0; j < trueP.length; j++) {
if(find(cur) == find(trueP[j])) {
isPossible = false;
break;
}
}
if(isPossible) {
result++;
}
}
System.out.println(result);
}
private static int find(int a) {
if(a == parent[a]) {
return a;
}
else {
return parent[a] = find(parent[a]);
}
}
private static void union(int a, int b) {
a = find(a);
b = find(b);
if(a != b) {
parent[b] = a;
}
}
}
53번 줄 세우기
내가 떠올린 풀이 해설
학생들을 노드로 생각하고, 키 순서 비교 데이터로 에지를 만든다고 생각했을 때 노드의 순서를 도출하는 가장 기본적인 문제이다. 특히 답이 여러 개일 때 아무것이나 출력해도 된다는 전제는 위상 정렬의 결괏값이 항상 유일하지 않다는 알고리즘의 전제와 동일하다는 것을 알 수 있다. 인접 리스트에 노드 데이터를 저장하고, 진입 차수 배열값을 업데이트한다. 위상 정렬 수행 과정은 진입 차수가 0인 노드를 큐에 저장한다 큐에서 데이터를 poll 해 해당 노드를 탐색 결과에 추가하고, 해당 노드가 가리키는 노드의 진입 차수를 1씩 감소한다. 감소했을 때 진입 차수가 0이 되는 노드를 큐에 offer 한다. 큐가 빌 때까지 반복한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek2252 {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
ArrayList<ArrayList<Integer>> list = new ArrayList<>();
for(int i = 0; i <= n; i++) {
list.add(new ArrayList<>());
}
int insert[] = new int[n + 1];
for(int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
int s = Integer.parseInt(st.nextToken());
int e = Integer.parseInt(st.nextToken());
list.get(s).add(e);
insert[e]++;
}
Queue<Integer> que = new LinkedList<>();
for(int i = 1; i <= n; i++) {
if(insert[i] == 0) {
que.offer(i);
}
}
while(!que.isEmpty()) {
int now = que.poll();
System.out.println(now );
for(int next : list.get(now)) {
insert[next]--;
if(insert[next] == 0) {
que.offer(next);
}
}
}
}
}
오늘의 회고
오늘은 union문제와 위상 정렬의 개념을 학습하고 위상 정렬을 적용하는 문제를 풀고 최근에 푼 문제부터 Do it! 알고리즘 코딩 테스트 (32번 ~ 35번) 까지 복습을 진행하였습니다. 반복해서 위상 정렬의 다른 문제가 나와도 막힘 없이 해결해 나아갈 수 있게 학습하겠습니다. 주말에 친구들과 시간을 보내고 쉬었으니 이번 주도 꾸준하게 공부하겠습니다.
도시 연결 유무를 유니온 파인드 연산을 이용해 해결할 수 있다는 아이디어를 떠올릴 수 있으면 쉽게 해결된다.
일반적으로 유니온 파인드는 그래프에서 많이 활용되지만, 위 문제와 같이 단독으로 활용할 수 있다는 점도 참고해야 된다.
인접 행렬을 탐색하면서 연결될 때마다 union연산을 수행하는 방식으로 풀어가면 된다. 도시와 여행 경로를 저장하고 각 노드와 관련된 대표 노드 배열의 값을 초기화한다. 도시 연결 정보가 저장된 인접 행렬을 탐색하면서 도시가 연결돼 있을 때 union연산을 수행한다. 이때 항상 큰 도시가 대표도시가 되도록 union 연산의 매개변수를 변경한다. 마지막으로 여행 경로에 포함된 도시의 대표 노드가 모두 같은지 확인한 후 출력하면 된다.
정확한 풀이
import java.util.*;
import java.io.*;
public class Baek1976 {
static int[] parent;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int m = Integer.parseInt(br.readLine());
int[][] arr = new int[n + 1][n + 1];
for(int i = 1; i <= n; i++) {
StringTokenizer st = new StringTokenizer(br.readLine());
for(int j = 1; j <= n; j++) {
arr[i][j] = Integer.parseInt(st.nextToken());
}
}
int[] route = new int[m + 1];
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i = 1; i <= m; i++) {
route[i] = Integer.parseInt(st.nextToken());
}
parent = new int[n + 1];
for(int i = 1; i <= n; i++) {
parent[i] = i;
}
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
if(arr[i][j] == 1) {
union(i, j);
}
}
}
// 여행 계획 도시들이 1개의 대표 도시로 연결돼 있는지 확인하기
int index = find(route[1]);
for(int i = 2; i < route.length; i++) {
if(index != find(route[i])) {
System.out.println("NO");
return;
}
}
System.out.println("YES");
}
private static void union(int i, int j) {
i = find(i);
j = find(j);
if(i != j) {
parent[j] = i;
}
}
private static int find(int j) {
if(parent[j] == j) {
return j;
}
else {
return parent[j] = find(parent[j]);
}
}
}
오늘의 회고
오늘은 union find 문제를 풀었습니다. 오늘까지 해서 복습은 마무리되었습니다. 복습으로 느낀 점은 알고리즘을 대비할 때 문제를 많이 풀려고 하지 말고 하나를 풀더라도 정확하게 이해하고 풀어야 한다고 느꼈습니다. 복습하면서 다시 푸는데 안 풀리는 문제들도 많았고 이해를 하면서 내 것으로 만드는 과정을 가지겠습니다.