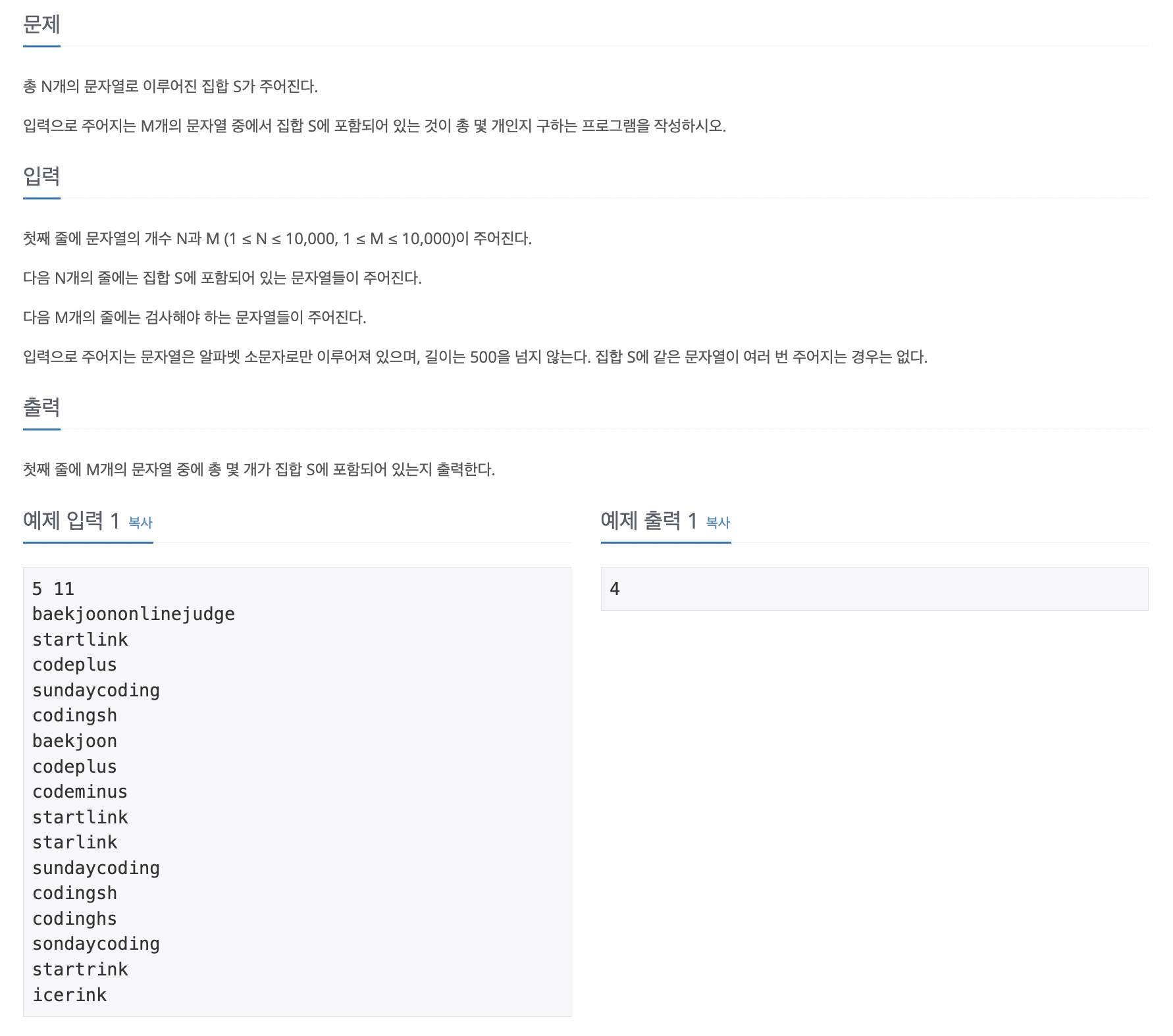
플로이드-위셜
그래프에서 최단 거리를 구하는 알고리즘으로, 주요 특징은 음수 가중치가 있어도 수행할 수 있고, 동적 계획법의 원리를 이용해 알고리즘에 접근한다.
시간 복잡도(노드수 : V)
O(V^3)
플로이드-위셜 핵심 이론
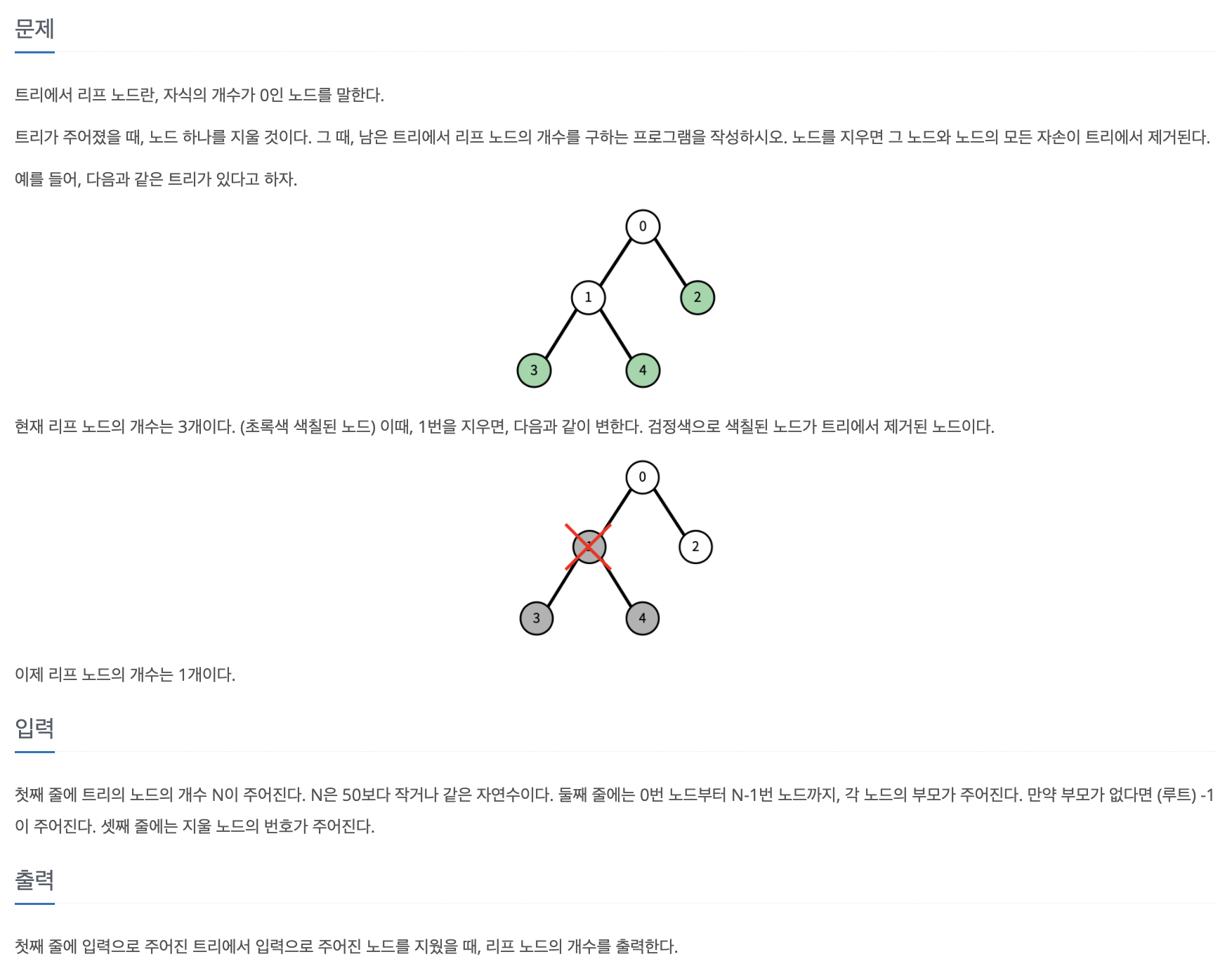
플로이드-위셜 알고리즘을 도출하는 가장 핵심적인 원리는 A 노드에서 B 노드까지 최단 경로를 구했다고 가정했을 때 최단 경로 위에 K 노드가 존재한다면 그것을 이루는 부분 경로 역시 최단 경로라는 것이다.
플로이드 위셜 점화식
D[S][E] = Math.min(D[S][E], D[S][K] + D[K][E])
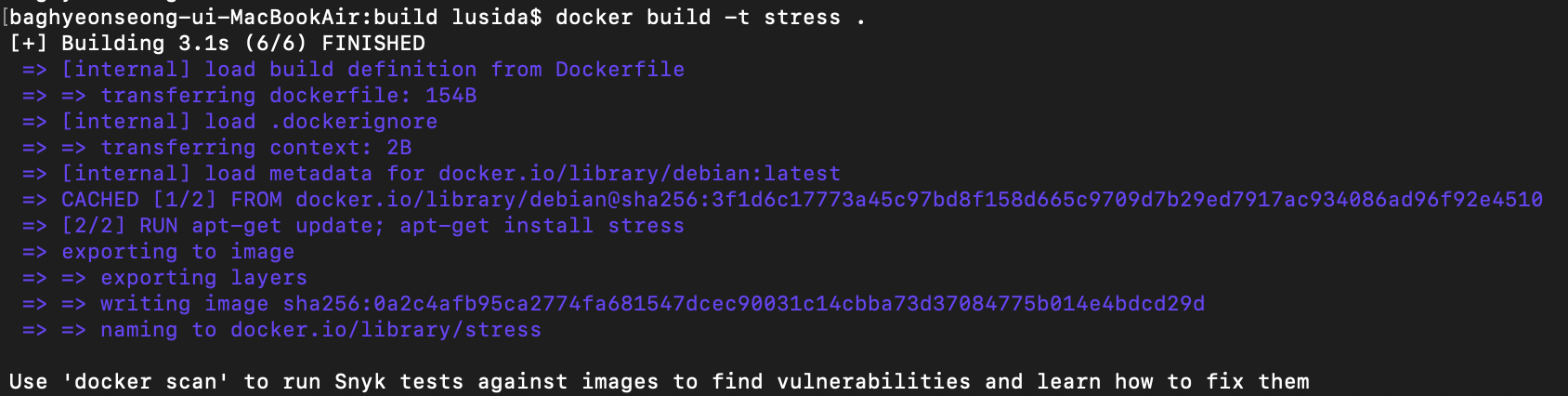
1. 배열을 선언하고 초기화하기
D[S][E]는 노드 S에서 노드 E까지의 최단 거리를 저장하는 배열이라 정의한다. S와 E의 값이 같은 같은 0, 다른 칸은 무한으로 초기화한다. 여기에서 S==E 는 자기 자신에게 가는 데 걸리는 최단 경로값을 의미하기 때문이다.
2. 최단 거리 배열에 그래프 데이터 저장하기
출발 노드는 S, 도착 노드는 E, 이 에지의 가중치는 W라고 했을 때 D[S][E] = W로 에지의 정보를 배열에 입력한다. 이로써 플로이드-위셜 알고리즘은 그래프를 인접 행렬로 표현한다는 것을 알 수 있다.
3. 점화식으로 배열 업데이트하기
기존에 구했던 점화식을 3중 for문 형태로 반복하면서 배열의 값을 업데이트한다.
플로이드-위셜 알고리즘 로직
for 경유지 K에 관해 (1 ~ N)
for 출발 노드 S에 관해 (1 ~ N)
for 도착 노드 E에 관해 (1 ~ N)
D[S][E] = Math.min(D[S][E], D[S][K] + D[K][E])
플로이드-위셜 알고리즘은 모든 노드 간의 최단 거리를 확인해 주기 때문에 시간 복잡도가 빠르지 않은 편이다. 플로이드-위셜 알고리즘을 사용해야 하는 문제가 나오면 일반적으로 노드의 개수의 범위가 다른 그래프에 적게 나타난다는 것을 알 수 있다.
코드로 표현
static int N,M;
static int distance[][];
distance = new int[n + 1][n + 1];
for(int i = 1; i <= N; i++) { // 인접 행렬 초기화
for(int j = 1; j <= N; j++) {
if(i == j) {
distance[i][j] = 0;
}
else {
distance[i][j] = 1000001; // 충분히 큰 수로 저장
}
}
}
for(int i = 0; i < M; i++) {
int s, e, v 입력받기
if(distance[s][e] > v) {
distance[s][e] = v;
}
}
for(int k = 1; k <= N; k++) { // 플로이드-위셜 알고리즘 수행하기
for(int i = 1; i <= N; i++) {
for(int j = 1; j <= N; j++) {
if(distance[i][j] > distance[i][k] + distance[k][j])
distance[i][j] = distance[i][k] + distance[k][j];
}
}
}
}
출력 부분