위상 정렬에서는 항상 유일한 값으로 정렬되지 않습니다. 또한 사이클이 존재하면 노드 간의 순서를 명확하게 정의할 수 없으므로 위상 정렬을 적용할 수 없습니다.
위상 정렬 핵심 이론
진입 차수는 자기 자신을 가리키는 에지의 개수이다. ArrayList로 그래프를 표현했다. 진입 차수 배열을 ArrayList로 표현한다. 만약 1에서 2, 3을 가리키면 D [2], D [3]을 각각 1만큼 증가시킨다.
진입 차수 배열에서 진입 차수가 0인 노드를 선택하고 선택된 노드를 정렬 배열에 저장한다. 그 후 인접리스트에서 선택된 노드가 가리키는 노드들의 진입 차수를 1씩 뺀다.
진입 차수가 0인 노드 1을 선택하여 2, 3의 진입 차수를 1씩 빼 D[2], D [3]을 0으로 만든다. 계속해서 모든 노드가 정렬될 때까지 반복한다. 여기서 진입 차수가 0인 노드를 위상 정렬 배열에 넣는다.
위상 정렬 수행 과정
진입 차수가 0인 노드를 큐에 저장
큐에서 데이터를 poll해 해당 노드를 탐색 결과에 추가하고, 해당 노드가 가리키는 노드의 진입 차수를 1씩 감소한다.
감소했을 때 진입 차수가 0이 되는 노드를 큐에 offer 한다.
큐가 빌 때까지 1 ~ 3을 반복한다.
시간 복잡도(노드 수: V, 에지 수: E)
O(V + E)
코드로 표현
ArrayList<ArrayList<Integer>> A = new ArrayList<>(); // 인접 리스트
for(int i = 0; i <= n; i++) {
A.add(new ArrayList<>());
}
int[] indegree = new int[n + 1]; // 진입 차수 배열
for(int i = 0; i < m; i++) {
int s = sc.nextInt();
int e = sc.nextInt();
A.get(s).add(e);
indegree[e]++; // 진입 차수 배열 데이터 저장하기
}
Queue<Integer> que = new LinkedList<>(); // 위상 정렬 수행하기
for(int i = 1; i <= n; i++) {
if(indegree[i] == 0) {
que.offer(i);
}
}
while(!que.isEmpty()) {
int now = que.poll();
for(int next : A.get(now)) {
indegree[next]--;
if(indegree[next] == 0) {
que.offer(next);
}
}
}
유니온 파인드는 일반적으로 여러 노드가 있을 때 특정 2개의 노드를 연결해 1개의 집합으로 묶는 union연산과 두 노드가 같은 집합에 속해 있는지를 확인하는 find 연산으로 구성되어 있는 알고리즘이다.
유니온 파인드 핵심 이론
union, find 연산
union 연산 : 각 노드가 속한 집합을 1개로 합치는 연산이다.
find 연산 : 특정 노드 a에 관해 a가 속한 집합의 대표 노드를 반환하는 연산이다.
유니온 파인드 원리 이해
유니온 파인드를 표현하는 일반적인 방식은 1차원 배열을 이용하는 것이다. 처음에는 노드가 연결되어 있지 않으므로 각 노드가 대표 노드가 된다. 각 노드가 모두 대표 노드이므로 배열은 자신의 인덱스 값으로 초기화한다. 2개의 노드를 선택해 각각의 대표 노드를 찾아 연결하는 union 연산을 수행한다. 배열을 보면 1, 4와 5, 6을 union연산으로 연결한다. 배열[4]은 1로, 배열[6]은 5로 업데이트한다. 1, 4의 연결을 예로 들어 1은 대표 노드, 4는 자식 노드로 union 연산을 하므로 배열[4]의 대표 노드를 1로 설정한 것이다. 다시 말해 자식 노드로 들어가는 노드 값 4를 대표 노드 값 1로 변경한 것이다. 그 결과 각각 집합이었던 1, 4는 하나로 합쳐진다. find 연산은 자신이 속한 집합의 대표 노드를 찾는 연산이다. find 연산은 단순히 대표 노드를 찾는 역할만 하는 것이 아니라 그래프를 정돈하고 시간 복잡도를 향상한다.
find 연산의 작동 원리
대상 노드 배열에 index값과 value값이 동일한지 확인
동일하지 않으면 value값이 가리키는 index위치로 이동
이동 위치의 index값과 value값이 같을 때까지 1, 2를 반복한다. 반복이므로 재귀 함수로 구현
대표 노드에 도달하면 재귀 함수를 빠져나오면서 거치는 모든 노드 값을 루트 노드 값으로 변경한다.
에지 리스트에 에지 정보를 저장한 후 부모 노드를 초기화한다. 사이클 생성 유무를 판단하기 위한 파인드용 부모 노드도 초기화한다. 크루스칼 알고리즘을 수행한다. 현재 미사용 에지 중 가중치가 가장 작은 에지를 선택하고, 이 에지를 연결했을 때 사이클의 발생 유무를 판단한다. 사이클이 발생하면 생략하고, 발생하지 않으면 에지 값을 더한다. 에지를 더한 횟수가 V(노드 개수) - 1 이 될 때까지 반복하고, 반복이 끝나면 에지의 가중치를 모두 더한 값을 출력한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek1197 {
static PriorityQueue<pEdge> que;
static int[] parent;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
parent = new int[n + 1];
que = new PriorityQueue<>();
for(int i = 0; i < n; i++) {
parent[i] = i;
}
for(int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
int c = Integer.parseInt(st.nextToken());
que.add(new pEdge(a, b, c));
}
int useEdge = 0;
int result = 0;
while(useEdge < n - 1) {
pEdge now = que.poll();
if(find(now.a) != find(now.b)) { // 같은 부모가 아니라면 연결해도 사이클이 생기지 않음
union(now.a, now.b);
result = result + now.c;
useEdge++;
}
}
System.out.println(result);
}
private static void union(int a, int b) {
a = find(a);
b = find(b);
if(a != b) {
parent[b] = a;
}
}
private static int find(int a) {
if(a == parent[a]) {
return a;
}
else {
return parent[a] = find(parent[a]);
}
}
}
class pEdge implements Comparable<pEdge>{
int a;
int b;
int c;
public pEdge(int a, int b, int c) {
this.a = a;
this.b = b;
this.c = c;
}
@Override
public int compareTo(pEdge o) {
return this.c - o.c;
}
}
66번 블우이웃 돕기
내가 떠올린 풀이 해설
인접 행렬의 형태로 데이터가 들어오기 때문에 이 부분을 최소 신장 트리가 가능한 형태로 변형하는 것이 이 문제의 핵심이다. 먼저 문자열로 주어진 랜선의 길이를 숫자로 변형해 랜선의 총합을 저장한다. 이때 i와 j가 같은 곳의 값은 같은 컴퓨터를 연결한다는 의미이므로 별도 에지로 저장하지 않고 나머지 위치의 값들을 i -> j로 가는 에지로 생성하고, 에지 리스트에 저장하면 최소 신장 트리로 변형할 수 있다.
입력 데이터의 정보를 배열에 저장한다. 먼저 입력으로 주어진 문자열을 숫자로 변환해 총합으로 저장한다. 소문자는 현재 문자 - 'a' + 1, 대문자는 현재 문자 - 'A' + 27 변환한다. i와 j가 다른 경우에는 다른 컴퓨터를 연결하는 랜선이므로 에지리스트에 저장한다. 저장된 에지 리스트를 바탕으로 최소 신장 트리 알고리즘을 수행한다. 최소 신장 트리의 결괏값이 다솜이가 최소한으로 필요한 렌선의 길이이므로 처음 저장해 둔 랜선의 총합에서 최소 신장 트리의 결괏값을 뺀 값을 정답으로 출력한다. 최소 신장 트리에서 사용한 에지 개수가 n - 1이 아닌 경우에는 모든 컴퓨터를 연결할 수 없다는 의미이므로 -1을 출력한다.
정확한 풀이
import java.io.*;
import java.util.*;
public class Baek1414 {
static int n, sum;
static PriorityQueue<lEdge> que;
static int[] parent;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
n = Integer.parseInt(br.readLine());
que = new PriorityQueue<>();
for(int i = 0; i < n; i++) {
StringTokenizer st = new StringTokenizer(br.readLine());
char[] tmpc = st.nextToken().toCharArray();
for(int j = 0; j < n; j++) {
int tmp = 0;
if(tmpc[j] >= 'a' && tmpc[j] <= 'z') {
tmp = tmpc[j] - 'a' + 1;
}
else if(tmpc[j] >= 'A' && tmpc[j] <= 'Z') {
tmp = tmpc[j] - 'A' + 27;
}
sum = sum + tmp;
if(i != j && tmp != 0) {
que.add(new lEdge(i, j, tmp));
}
}
}
parent = new int[n];
for(int i = 0; i < n; i++) {
parent[i] = i;
}
int useEdge = 0;
int result = 0;
while(!que.isEmpty()) {
lEdge now = que.poll();
if(find(now.s) != find(now.e)) {
union(now.s, now.e);
result = result + now.v;
useEdge++;
}
}
if(useEdge == n - 1) {
System.out.println(sum - result);
}
else {
System.out.println(-1);
}
}
private static void union(int s, int e) {
s = find(s);
e = find(e);
if(s != e) {
parent[e] = s;
}
}
private static int find(int s) {
if(s == parent[s]) {
return s;
}
else {
return parent[s] = find(parent[s]);
}
}
}
class lEdge implements Comparable<lEdge> {
int s;
int e;
int v;
public lEdge(int s, int e, int v) {
this.s = s;
this.e = e;
this.v = v;
}
@Override
public int compareTo(lEdge o) {
return this.v - o.v;
}
}
오늘의 회고
오늘은 최소 신장 트리 문제 2문제를 풀었습니다. 코드를 구현하는데 어려웠습니다. 반복해서 제가 직접 구현할 수 있게 만들겠습니다. 오늘 날씨가 너무 더운데 모든 취준생분들 화이팅입니다. 열심히 나아가겠습니다. 모두 화이팅입니다.
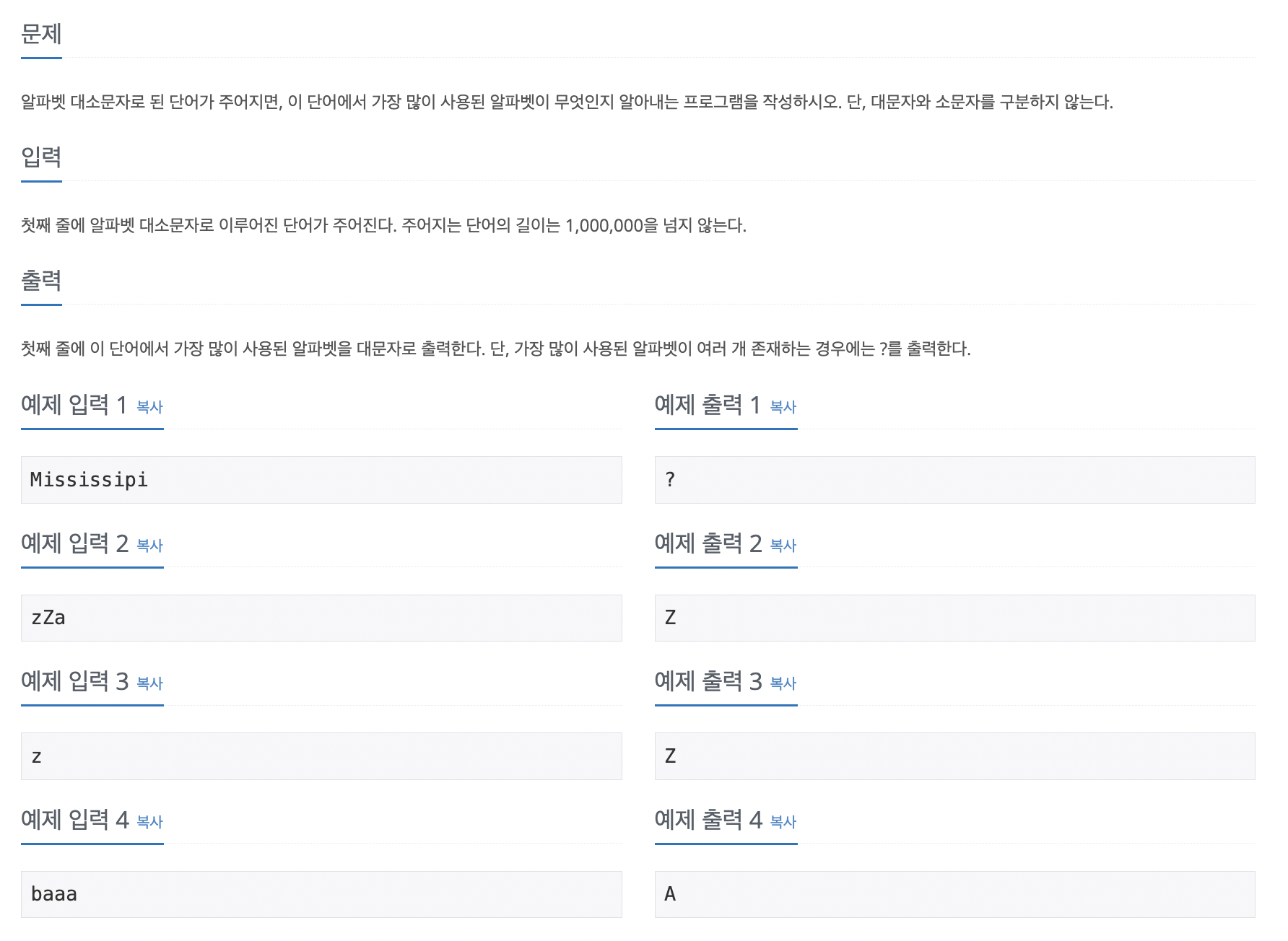
정답 출력을 다 대문자로 진행하기 때문에 문자를 다 대문자로 바꾸어 준 후 알파벳 개수만큼 배열을 생성한다. for 문에 i = 0부터 i < str.length()까지 하나씩 탐색하면서 입력받은 문자에서 - 65를 해준다. (arr [str.charAt(i) - 65]++ ) max값을 arr [str.charAt(i) - 65]로 바꾸어준다. 또한 ch에 그 단어를 저장해준다. 만약 max값이랑 arr [str.charAt(i)]값이랑 같으면 ch에 '?'를 저장해준다. for문을 끝내고 ch를 출력해준다.
정확한 풀이
import java.util.*;
import java.io.*;
public class Baek1157 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String str = br.readLine();
str = str.toUpperCase();
int[] arr = new int[26];
int max = -1;
char ch = '?';
for(int i = 0; i < str.length(); i++) {
arr[str.charAt(i) - 65]++;
if(max < arr[str.charAt(i) - 65]) {
max = arr[str.charAt(i) - 65];
ch = str.charAt(i);
}
else if(max == arr[str.charAt(i) - 65]) {
ch = '?';
}
}
System.out.println(ch);
}
}
오늘의 회고
프로젝트 리펙토링을 진행하다가 댓글 화면이 안 나오는데 일주일 넘게 이를 잡고 있습니다. 오늘 해결해 보려고 했는데 오늘도 실패해서 하고 싶은 생각이 안 들어 머리를 좀 식힐 겸 알고리즘 쉬운 문제를 한 문제를 풀었습니다. 하지만 아이디어를 떠올리는데 시간이 걸렸습니다. 알파벳만큼 배열을 만들어 문자 - 65를 하면 그 문자의 위치에 더해준다는 것을 못 떠올렸습니다. ㅠㅠ 아직 갈길이 먼 것 같습니다.