728x90
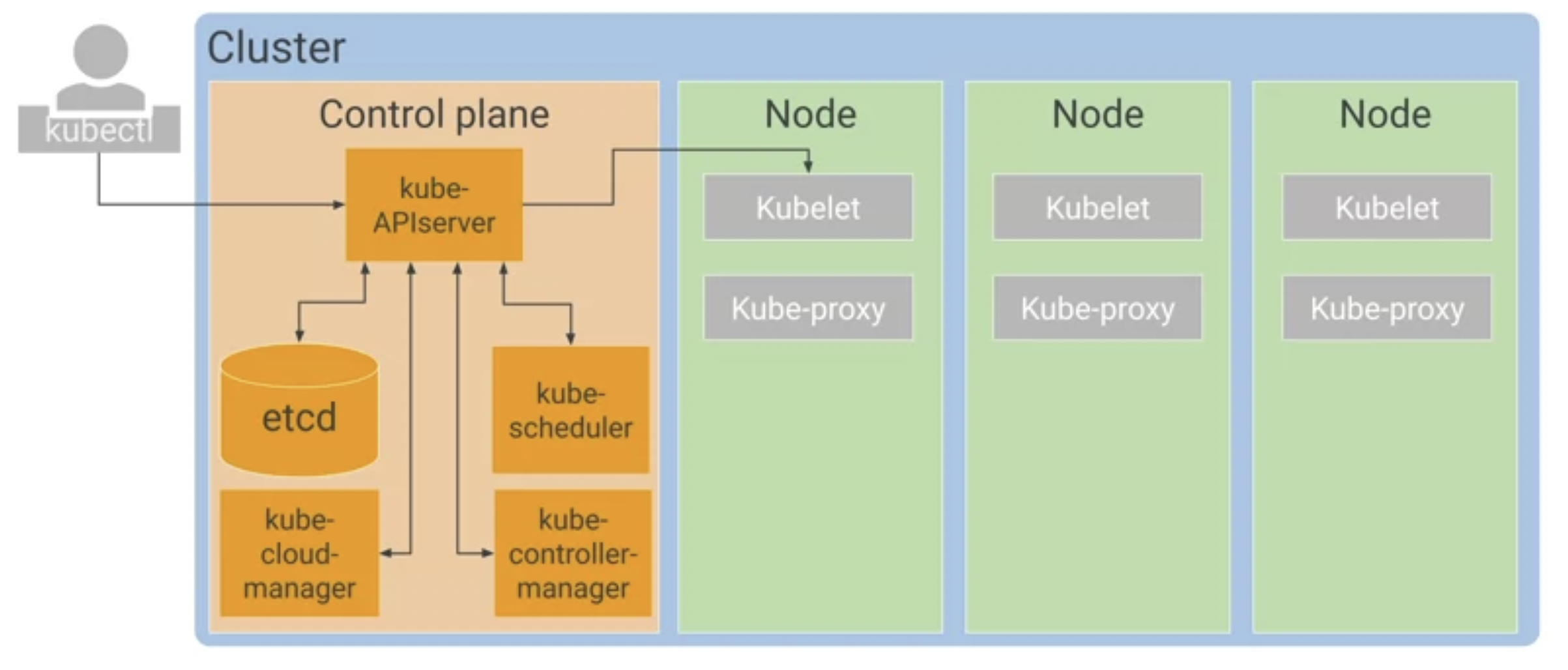
Kubernetes 네트워킹 모델
- IP 주소에 크게 의존합니다.
- 서비스, pod, 컨테이너, 노드는 IP 주소와 포트를 사용하여 통신합니다.
- Kubernetes는 트래픽을 올바른 pod로 전달하기 위해 여러 유형의 부하 분산을 제공합니다.
pod 네트워킹

- pod는 공유 스토리지와 네트워킹이 포함된 컨테이너 그룹입니다.
- Kubernetes의 'pod별 IP' 모델을 기반으로 한다. 이 모델에서는 각 pod에 단일 IP 주소가 할당되고 pod 내의 컨테이너는 해당 IP 주소를 포함하여 동일한 네트워크 네임스페이스를 공유합니다.
pod 네트워킹의 예

- 기존 애플리케이션에서 클라이언트 액세스를 위해 nginx를 역방향 프록시로 사용하고 있을 수 있습니다.
- nginx 컨테이너는 TCP 포트 80에서 실행되고 기존 애플리케이션은 TCP 포트 8000에서 실행됩니다.
- 두 컨테이너 모두 동일한 네트워킹 네임스페이스를 공유하기 때문에 두 컨테이너는 동일한 머신에 설치된 것처럼 보입니다.
- nginx 컨테이너는 TCP 포트 8000에서 localhost에 대한 연결을 설정하여 기존 애플리케이션에 연결합니다.
- 단일 pod에서는 이것이 효과적이지만 워크로드는 단일 pod에서 실행되지 않습니다.
- 워크로드는 서로 통신해야 하는 다양한 애플리케이션으로 구성됩니다.
pod는 서로 어떻게 통신할까

- 각 pod에는 고유한 IP 주소가 있습니다 네트워크에 있는 호스트처럼
- 노드에서 pod는 노드의 루트 네트워크 네임스페이스를 통해 서로 연결되며 이를 통해 해당 VM에서 pod가 서로를 찾고 연결할 수 있습니다.
- 루트 네트워크 네임스페이스는 노드의 기본 NIC에 연결되어 있습니다.
- 노드의 VM NIC를 사용하여 루트 네트워크 네임스페이스는 해당 노드에서 트래픽을 전달할 수 있습니다. 즉, pod의 IP 주소를 노드가 연결된 네트워크에서 라우팅 할 수 있어야 한다는 뜻입니다.

노드는 해당 pod의 IP 주소를 어디에서 얻을까

- GKE에서 노드는 Virtual Private Cloud 즉, VPC에 할당된 주소 범위에서 pod IP 주소를 가져옵니다.
VPC
- VPC는 GCP 내에서 배포하는 리소스에 대한 연결을 제공하는 논리적으로 격리된 네트워크입니다.
- VPC는 전 세계 모든 리전의 다양한 IP 서브넷으로 구성될 수 있습니다.
- GKE를 배포할 때 리전 또는 영역과 함께 VPC를 선택할 수 있습니다.
- 기본적으로 VPC에는 전 세계의 각 GCP 리전에 미리 할당된 IP 서브넷이 있습니다. 서브넷의 IP 주소는 해당 리전에 배포하는 컴퓨팅 인스턴스에 할당됩니다.
Kubernetes의 스토리지 추상화
- 볼륨
- PersistentVolume
볼륨
- 볼륨은 스토리지를 pod에 연결하는 수단입니다.
- 어떤 볼륨은 임시적입니다. pod에 연결된 시간 동안에만 유지된다는 뜻
- 어떤 볼륨은 영구적입니다 pod보다도 오래 유지될 수 있다는 뜻
- 유형에 상관없이 모든 볼륨은 컨테이너가 아닌 pod에 연결됩니다.
- pod가 더 이상 노드에 매핑되지 않으면 볼륨도 매핑되지 않습니다.
- 영구적인 스토리지를 제공하는 데 활용 가능한 다른 볼륨 유형도 있습니다
- 이러한 유형(??)은 개별 pod의 수명보다 오래 지속되어야 하는 데이터에 사용할 수 있습니다.
- Kubernetes 클러스터에서는 이러한 볼륨 유형이 NFS 볼륨, Windows 공유 또는 기본 클라우드 제공업체의 영구 디스크에서 지원되는 경우가 많습니다.
- 이러한 유형의 볼륨은 블록 스토리지를 포함하거나 네트워크 파일 시스템을 사용합니다.
- 장애가 발생한 pod에서는 볼륨이 마운트 해제됩니다.
- 이러한 볼륨 중 일부는 pod 생성 이전에 이미 존재할 수 있으며 클레임이나 마운트할 수도 있습니다.
- 중요한 것은 볼륨이 pod의 컨테이너에 액세스 가능한 디렉터리라는 것입니다.
- 이 디렉터리의 생성 방식과 디렉터리와 그 안의 콘텐츠를 지원하는 매체는 사용된 특정한 볼륨에 의해 결정됩니다.
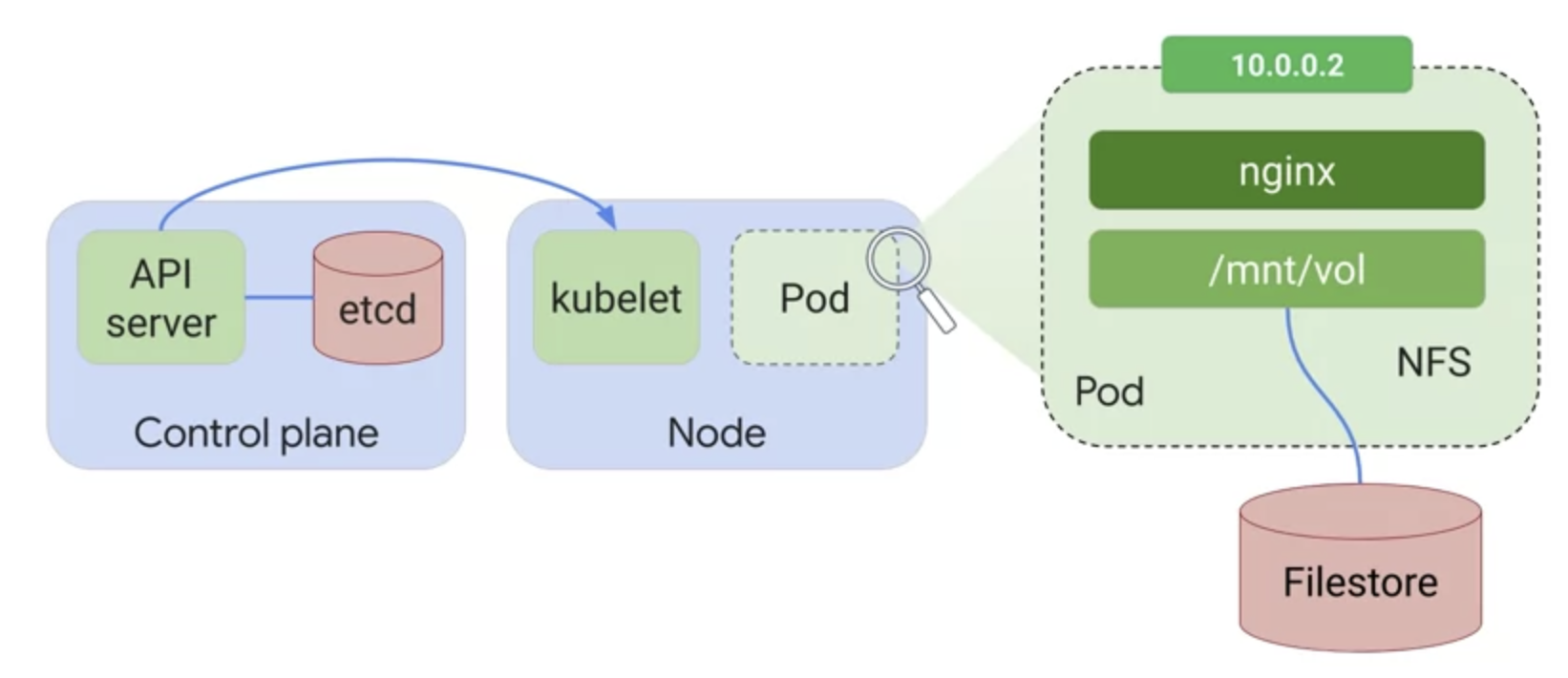
10. 볼륨을 컨테이너에 표시하려면 컨테이너의 volumeMounts 필드에 볼륨 이름과 마운트 경로를 지정해야 합니다.
- pod 생성 중에 볼륨이 만들어집니다. 볼륨이 만들어지면 컨테이너를 온라인으로 가져오기 전에 pod의 모든 컨테이너에서 사용 가능합니다. 볼륨이 컨테이너에 연결된 후 볼륨의 데이터는 컨테이너 파일 시스템에 마운트 됩니다.
- 볼륨은 pod가 실행될 때 마운트 볼륨 디렉터리에 연결됩니다 그런 다음 nginx 컨테이너는 /mnt/vol 디렉터리를 보고 여기에서 데이터를 가져올 수 있습니다.
11. pod가 삭제되면 함께 지워지는 emptyDir 볼륨의 콘텐츠와 다르게 NFS 볼륨에 저장된 데이터는 pod가 삭제되어도 유지됩니다.
- pod가 삭제되면 NFS 볼륨도 삭제되지만 데이터는 지워지지 않습니다.
- 마운트 해제되는 것뿐이며 필요하면 새 pod에 다시 마운트 할 수 있습니다.
Kubernetes PersistentVolume 객체
- 스토리지 사용을 토대로 스토리지 프로비저닝을 추상화합니다.
- Kubernetes 덕분에 마이크로 서비스 아키텍처에서 애플리케이션을 쉽게 확장할 수 있는 구성요소로 분리할 수 있는 것입니다.
- 영구 스토리지를 사용하면 장애에 대처하고 데이터 손실 없이 구성요소 예약을 동적으로 변경할 수 있습니다.
애플리케이션 구성요소를 위해 분리된 볼륨을 만들고 유지 관리하는 작업이 애플리케이션 개발자의 몫이어야 할까? 또한 개발자가 애플리케이션의 pod 매니페스트를 수정하지 않고 프로덕션에 배포하기 전에 애플리케이션을 어떻게 테스트할까?
- 테스트에서 프로덕션 단계로 나아가기 위해 구성을 변경해야 할 때마다 오류의 위험이 있습니다.
- Kubernetes의 PersistentVolume 추상화는 이러한 문제를 모두 해결합니다.
- PersistentVolume을 사용하여 클러스터 관리자는 다양한 볼륨 유형을 프로비저닝 할 수 있습니다.
- 클러스터 관리자는 사용에 대해 신경 쓰지 않고 스토리지를 프로비저닝 하면 됩니다.
- 또한 애플리케이션 개발자는 PersistentVolumeClaim을 사용하여 스토리지 볼륨을 직접 만들거나 유지 관리하지 않고도 프로비저닝 된 스토리지를 쉽게 클레임하고 사용할 수 있습니다.
역할의 분리
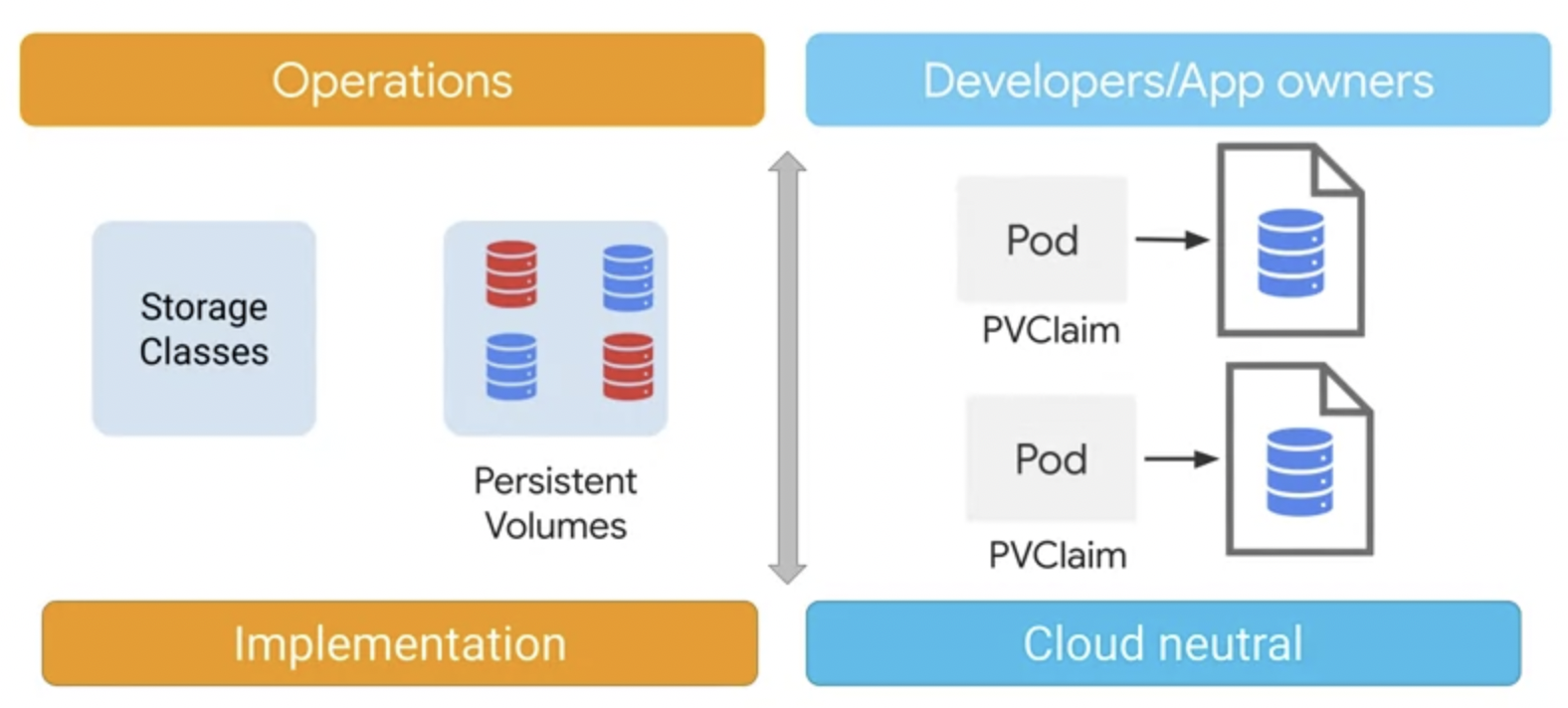
PersistentVolume을 사용할 수 있도록 만드는 것은 관리자의 몫이고 애플리케이션에서 이러한 볼륨을 사용하는 것은 개발자의 몫입니다. 이 두 작업 역할은 서로 독립적으로 이루어질 수 있습니다.
애플리케이션 개발자는 PersistentVolumeClaim을 사용할 때 애플리케이션 실행 위치를 신경 쓸 필요가 없습니다. 프로비저닝된 스토리지 용량은 애플리케이션에 의해 클레임 될 수 있는데 실행 위치가 로컬 사이트나 Google Cloud 혹은 다른 클라우드 제공업체든 상관없죠
애플리케이션 소유자가 Compute Engine 영구 디스크 스토리지를 사용하려면 무엇이 필요한가?
- pod 수준의 볼륨을 사용하는 경우
- pod 매니페스트에서 클러스터 수준의 PersistentVolume과 PersistentVolumeClaim을 사용하는 경우
- 두 번째 방법이 관리하기 쉽다.
- 클라우드 구현을 책임지는 운영팀에서는 PersistentVolume을 사용하기 위해 스토리지 클래스를 정의하고 PersistentVolume의 실제 구현을 관리합니다.
- 개발자와 애플리케이션 소유자는 PersistentVolumeClaim을 사용하여 스토리지의 양과 스토리지 클래스를 요청하고 그에 따라 스토리지 유형이 결정됩니다.
- 운영팀은 사용하려는 클라우드 서비스를 관리할 수 있으며 애플리케이션 소유자는 특정 구현의 세부사항보다는 애플리케이션이 필요로 하는 것에 집중할 수 있습니다.
- Kubernetes 엔진은 PersistentVolume에 대해 이와 동일한 기술을 사용한다.
- Google Cloud의 Compute Engine 서비스는 가상 머신 디스크에 영구 디스크를 사용합니다.
영구 디스크
- 영구 디스크는 오래 지속되는 스토리지를 제공할 수 있는 네트워크 기반 블록 스토리지입니다.
영구 볼륨 추상화의 두 가지 구성요소
- PersistentVolume
- PersistentVolumeClaim
영구 볼륨
- 클러스터 수준에서 관리되는 내구성이 뛰어난 영구 스토리지 리소스입니다.
- 클러스터 리소스는 pod의 수명 주기와 무관하지만 pod는 수명 주기 동안 이러한 리소스를 사용할 수 있습니다. 하지만 pod가 삭제되더라도 영구 볼륨과 해당 데이터는 계속 존재합니다. 볼륨은 Kubernetes에서 관리하며 수동으로 또는 동적으로 프로비저닝 할 수 있습니다.
PersistentVolumenClaim
- PersistentVolume을 사용하도록 pod가 만든 요청 및 클레임입니다.
- PersistentVolumeClaim 객체 내에서 볼륨 크기, 액세스 모드 및 스토리지 클래스를 정의합니다.
- pod는 PersistentVolumeClaim을 사용하여 영구 볼륨을 요청합니다.
- 영구 볼륨이 영구 볼륨 신청에 정의된 모든 요구사항과 일치하는 경우 영구 볼륨 신청은 해당 영구 볼륨에 바인딩됩니다. 이제 pod는 이 영구 볼륨에서 스토리지를 사용할 수 있습니다.
스토리지 클래스
- 이름을 지정한 스토리지 특성의 세트입니다.
스토리지용으로 pod 수준 볼륨을 사용하는 것과 클러스터 수준 영구 볼륨을 사용하는 것의 중요한 차이점은 무엇일까?
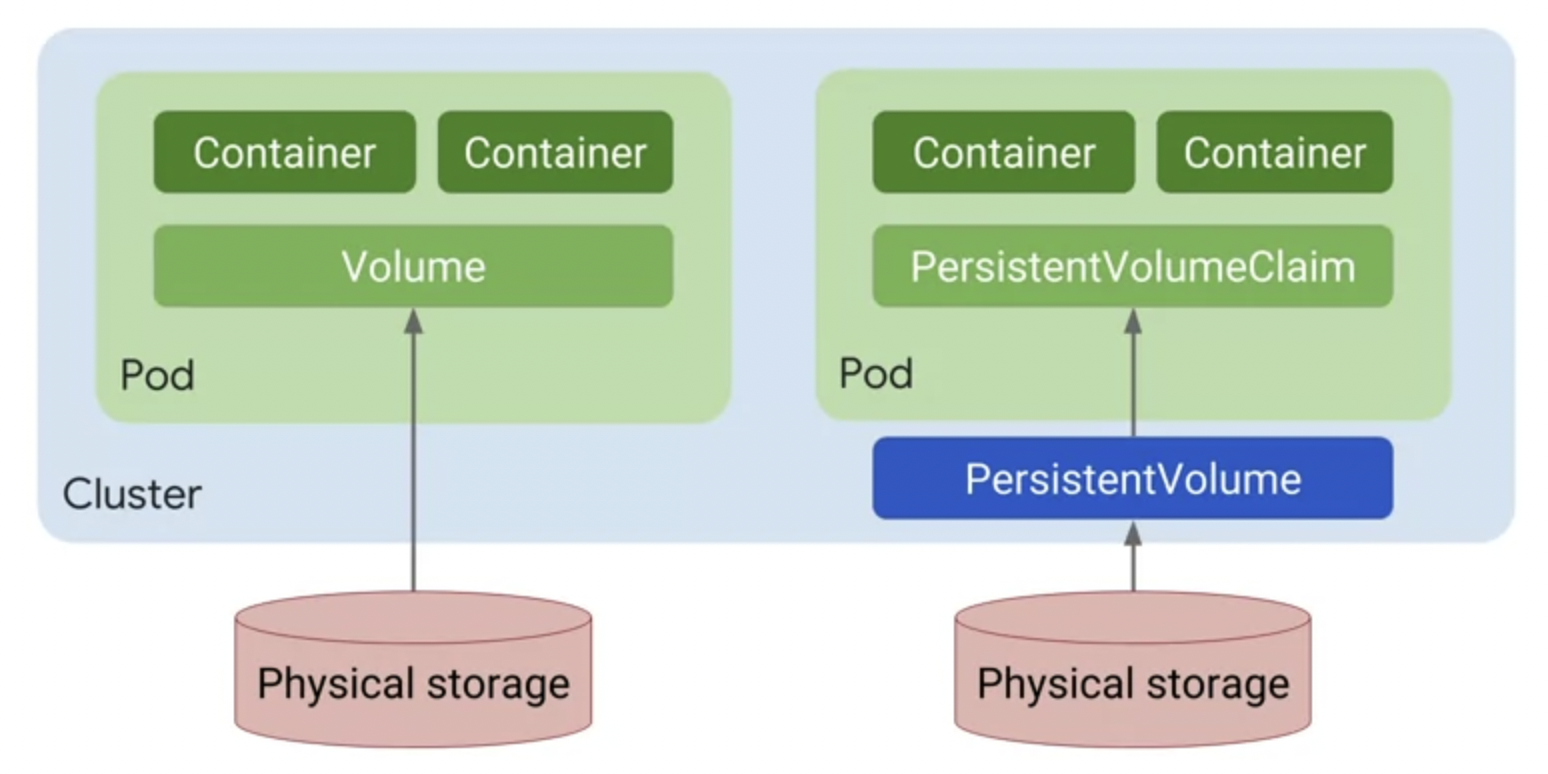
- 영구 볼륨은 애플리케이션 구성에서 스토리지 관리를 분리할 수 있는 추상화 수준을 제공합니다.
- 영구 볼륨의 스토리지는 영구 볼륨 신청과 바인딩되어야 pod에서 액세스 할 수 있습니다.
- 이것은 같은 스토리지에 대한 영구 볼륨 매니페스트를 생성하는 방법입니다.
pod의 스토리지 구성을 더 쉽게 관리하기 위해 이것이 어떻게 사용되는가?
- 먼저 볼륨 용량을 지정하고 StorageClassName을 지정합니다.
- 스토리지 클래스는 영구 볼륨을 구현하는 데 사용되는 리소스입니다.
- pod에서 PVC를 정의할 때 PVC는 스토리지 클래스 이름을 사용합니다. 클레임이 성공하려면 PV StorageClassName과 일치해야 합니다.
SSD 영구 디스크를 사용하려는 경우
- 이름이 'ssd'인 이 예처럼 새 스토리지 클래스를 생성할 수 있습니다.
- ssd라는 이 새로운 스토리지 클래스를 사용하는 PVC는 ssd라는 스토리지 클래스가 있는 PV만 사용합니다. 이 경우 SSD 영구 디스크를 사용합니다.
현대적이고 관리하기 쉬운 방법은 영구 볼륨 추상화를 사용하는 것입니다.
이상으로 2022 Cloud Study Jam 쿠버네티스 중급반 과정을 수료하였습니다.

728x90