전체적인 구성
- 로컬 PC에서 개발을 한 후 Github에 Push를 합니다.
- Github Repository 특정 branch에 push가 되면 Github Action이 동작을 시작합니다.
- Github Actions가 Github Container Registry에 소스를 받은 후 Docker 이미지로 빌드를 합니다.
- 빌드된 이미지를 EC2에 등록된 Runner가 복사합니다.
- 기존 이미지를 삭제하고 새로운 이미지로 실행을 합니다.
흐름도

- 형상관리 : Git (Github)
- 빌드 : Docker (Github Action)
- 서버 : Linux (AWS EC2 micro)
순서
- Docker로 로컬 테스트
- Github Actions
- AWS EC2 생성 및 Docker 설치
- 자동 배포 테스트
IntelliJ에서 설정
- gradle에서 build bootJar 더블클릭하면 build 폴더에 libs에 .jar 파일 생성됨

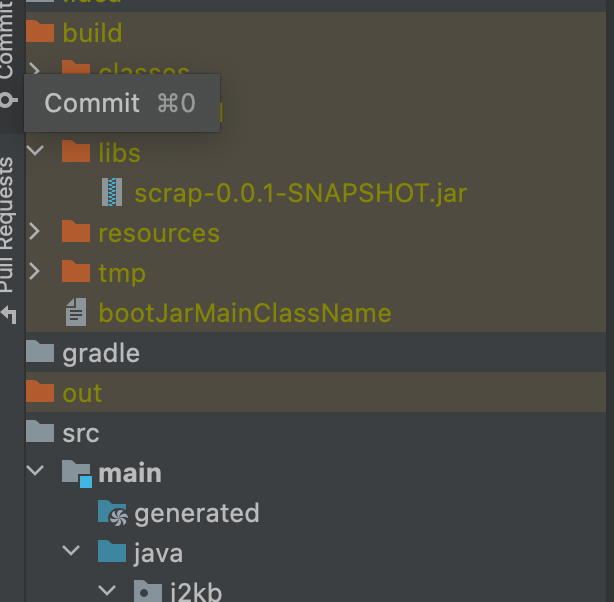
스프링에서 libs에 스프링부트 2.5.0이후 plain.jar가 만들어지기때문에 꺼두었습니다.
jar {
enabled = false
}
Docker로 로컬 테스트
- Docker 이미지를 만들기 위해 프로젝트 루트에 Dockerfile을 아래와 같이 생성합니다.
FROM openjdk:11
ARG JAR_FILE=*.jar
COPY ${JAR_FILE} app.jar
ENTRYPOINT ["java","-jar","/app.jar"]
# FROM : Docker Base Image (기반이 되는 이미지, <이미지 이름>:<태그> 형식으로 설정, java8로 코드를 작성했다면 11대신 8로 넣어줘야 합니다.)
# ARG : 컨테이너 내에서 사용할 수 있는 변수를 지정할 수 있다.
# COPY : 위에 선언했던 JAR_FILE 변수를 컨테이너의 app.jar로 복사한다.
# ENTRYPOINT : 컨테이너가 시작되었을 때 스크립트 실행
- cd 명령어를 통해 jar 파일이 있는 곳으로 터미널 위치를 옮긴다. (cd build/libs)
- 이미지를 생성 합니다.
docker build -t springio/scrap-spring-boot-docker .
# docker build -t {이미지명} .
- 생성되었는지 확인
docker images
빌드가 완료되었다면 다음 명령어를 터미널에 입력해 springio/scrap-spring-boot-docker이 생성되었는지 확인한다.
- 컨테이너 실행하기
docker run -d -p 5000:8080 springio/scrap-spring-boot-docker
# 현재 내 로컬에서 5000port 사용으로 8083으로 변경
- 로컬에서 실행되는지 테스트

GitHub 설정
- .dockerignore파일 작성
.idea/
*.iml
*.iws
target/
.sonar/
.sonarlint/
- 프로필 우측에있는 화살표를 눌러 Settings에 들어간다.

- Settings 제일 밑 하단에 Developer settings에 들어간다.
- 왼쪽 메뉴에 Personal access tokens를 누르고 Generate new token 을 클릭한다.

- 토큰의 유효기간과 권한을 설정합니다.

- 유효기간은 최대 1년까지 가능합니다.
- 권한은 workflow, write:packages, delete:packages를 선택합니다.
- Generate token을 누르면 토큰이 생성된다.
- 생성한 토큰을 복사해서 배포를 진행할 레파지토리로 이동한다.

상위 메뉴의 Settings에 들어가 왼쪽 하단 메뉴의 Secrets의 Actions에 들어간다.
왼쪽 상단에 있는 New repository secret을 누른다.
- 이름을 지정하고 복사했던 토큰을 붙여넣어준다.

- dockerHub USERNAME과 PASSWORD를 작성한다.

- 아래와 같이 workflow 파일을 작성합니다.
이것은 Github Container Registry를 이용해서 docker를 빌드하고 서버에 푸시해주는 역할을 합니다.(.github/workflows/main.yml)

# This workflow uses actions that are not certified by GitHub.
# They are provided by a third-party and are governed by
# separate terms of service, privacy policy, and support
# documentation.
# This workflow will build a Java project with Gradle and cache/restore any dependencies to improve the workflow execution time
# For more information see: https://help.github.com/actions/language-and-framework-guides/building-and-testing-java-with-gradle
name: Java CI with Gradle
on:
push:
branches: [ "master" ]
pull_request:
branches: [ "master" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up JDK 11
uses: actions/setup-java@v3
with:
java-version: '11'
distribution: 'temurin'
- name: Build with Gradle
uses: gradle/gradle-build-action@67421db6bd0bf253fb4bd25b31ebb98943c375e1 # 수정해야함
with:
arguments: build
- name: Docker build
run: |
docker login -u ${{ secrets.USERNAME }} -p ${{ secrets.PASSWORD }}
docker build -t spring-cicd .
docker tag spring-cicd lusida0131/spring-cicd:latest
docker push lusida0131/spring-cicd:latest
deploy:
needs: build # build 후에 실행되도록 정의
name: Deploy
runs-on: [ self-hosted, label-go ] # AWS ./configure에서 사용할 label명
steps:
# 3000 -> 80 포트로 수행하도록 지정
- name: Docker run
run: |
docker login -u ${{ secrets.USERNAME }} -p ${{ secrets.PASSWORD }}
docker stop spring-cicd && docker rm spring-cicd && docker rmi lusida0131/spring-cicd:latest
docker run -d -p 8080:8080 --name spring-cicd --restart always lusida0131/spring-cicd:latestworkflow파일 설명
on:
push:
branches: [ main ]- 여러 브랜치에서 개발 후 main 브랜치에 push or 병합될 때만 실행되도록 설정한다.
jobs:
build:
runs-on: ubuntu-latest
steps:- Workflow는 다양한 job으로 구성되고 위 yml은 build와 deploy라는 job을 생성한다.
- runs-on은 어떤 OS에서 실행될지를 지정한다.
- uses: actions/checkout@v3- build의 step 첫 번째는 현재 상태의 소스코드를 가상의 컨테이너 안으로 checkout 해주는 역할
- name: Set up docker buildx
id: buildx
uses: docker/setup-buildx-action@v1
- build의 step 두 번째는 가상의 컨테이너 안에 docker가 돌아갈 수 있는 환경을 설치하는 역할
- name: Set up JDK 11
uses: actions/setup-java@v3
with:
java-version: '11'
distribution: 'temurin'- build의 step 두 번째는 JDK 11을 설치한다.
- name: Docker build
run: |
docker login -u ${{ secrets.USERNAME }} -p ${{ secrets.PASSWORD }}
docker build -t spring-cicd .
docker tag spring-cicd lusida0131/spring-cicd:latest
docker push lusida0131/spring-cicd:latest- build의 step 네 번째는 Secret에 설정해놓은 USERNAME과 PASSWORD로 도커허브에 로그인해서 Docker image를 만들고 push한다.
deploy:
needs: build # build 후에 실행되도록 정의
name: Deploy
runs-on: [ self-hosted, label-go ] # AWS ./configure에서 사용할 label명
steps:
# 3000 -> 80 포트로 수행하도록 지정
- name: Docker run
run: |
docker login -u ${{ secrets.USERNAME }} -p ${{ secrets.PASSWORD }}
docker stop spring-cicd && docker rm spring-cicd && docker rmi lusida0131/spring-cicd:latest
docker run -d -p 8080:8080 --name spring-cicd --restart always lusida0131/spring-cicd:latest- Deploy는 Docker에 로그인 후 저장되어 있는 Docker image를 이용해 컨테이너를 실행시키는 역할
- Docker run은 실행 중인 도커 컨테이너를 중지하고 이전 버전인 컨테이너와 이미지를 삭제 후 새로운 이미지로 컨테이너를 run하는 방식이다.
- runs-on 중 self-hosted는 필수로 써야한다.(이 값을 설정해야 서버에 등록한 runner가 실행된다.)
- 이 부분에서 어느 Runner(EC2)로 실행할지 지정해줘야 한다.
AWS EC2 생성 및 Docker 설치
- EC2 보안그룹 편집, 규칙추가 버튼을 누르고 8081번 port를 추가
- EC2에 Docker 설치 방법
sudo apt-get update
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-releaseapt가 HTTPS 프로토콜을 통해서 repository를 사용할 수 있도록 패키지를 설치한다.
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgDocker의 공식 GPG key를 추가한다.
echo \
"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullapt source list에 repository를 추가한다.
sudo apt-get update
$ sudo apt-get install docker-ce
apt package index를 update하고 Docker를 설치한다.
sudo service docker start # Docker 서비스를 시작합니다.
ps -ef|grep docker # 프로세스 확인 명령어
sudo usermod -a -G docker ubuntu # sudo를 사용하지 않고도 Docker 명령을 실행할 수 있도록 docker 그룹에 ec2-user를 추가합니다.
sudo usermod -aG docker $USER
docker ps 명령어를 실행했을때 아래와 같은 오류가 발생하면 docker.sock 권한을 바꾸어준다.
docker ps
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/json": dial unix /var/run/docker.sock: connect: permission denied
sudo chmod 666 /var/run/docker.sock # sudo를 사용하지 않고도 명령을 실행하게 docer.sock 권한을 바꾸어준다.
- AWS에 Github Runner 설치

해당 Repository에 Settings에 들어가서 왼쪽 메뉴 Actions의 Runners를 클릭한다.
- Download에 있는 내용, Configure을 EC2서버에 복사해서 한 줄씩 실행시킨다.

하단의 Configure도 위와 동일하게 실행
- Enter the name of the runner group to add this runner to : 엔터
- Enter the name of runner : 엔터
- Configure 진행할 때 Enter any additional labels가 나오면 아래에 있는 label-go를 등록한다.
- Enter name of work folder : 엔터
deploy:
needs: build # build 후에 실행되도록 정의
name: Deploy
runs-on: [ self-hosted, label-go ] # AWS ./configure에서 사용할 label명
- Configure에 ./run.sh는 nohup으로 실행
nohup ./run.sh &
- Runner 세팅이 끝나면 github의 Settings - Actions - Runner 메뉴에서 등록된 것을 확인할 수 있습니다.
참고 블로그
https://velog.io/@soosungp33/Github-Actions으로-AWS-EC2에-CICD-구축하기
Github Actions으로 AWS EC2에 CI/CD 구축하기
AWS EC2에 CI/CD 구축하기
velog.io
https://codegear.tistory.com/84?category=985388
배포자동화(CI/CD) - Github Actions/Nuxtjs/Docker/EC2
다음은 이 글의 유튜브 영상입니다. https://youtu.be/E3i9qt0SS-I 프로젝트를 진행할때 많은 시간을 들여야 하는 것 중에 하나가 바로 배포입니다. 형상관리(Git)에 커밋을 하고, 서버에 파일을 업로드
codegear.tistory.com
'프로젝트 > 스크랩' 카테고리의 다른 글
| 스크랩 프로젝트를 진행하면서 현재 고민하고 있는 문제 (0) | 2022.10.21 |
|---|---|
| 서버와 로컬에서 특정 URL의 테스트 값이 다름 (0) | 2022.10.17 |
| YML 설정 파일 암호화 (0) | 2022.10.12 |
| Swagger 서버에 배포시 curl 수정 (0) | 2022.10.07 |
| Swagger API 설정 방법, 실행 (0) | 2022.09.30 |